Module 6: Overview of System Architecture
Welcome to the module Overview of System Architecture. This module explores the value in using system architecture to plan and describe a health information system. It examines four types of system architecture. This module complements the module on System Classification, in which we look at the logic underlying information systems, the logic model, and how to classify or describe different elements of a system. Read the learning objectives to discover what you will learn in this module. Read the learning objectives to discover what you will learn in this module.
Learning Objectives
By the end of this module, you will be able to:
- Explain the value of using different information systems for different purposes
- Describe four different information system architectures
- Identify advantages and limitations of each architecture
Learning Activities
-
Reading: Bringing Order to Chaos (5 min)
The principal question in this introduction to health information systems is: how will people involved in clinical care, programme management, and policy-making access and use data gathered at health facilities in order to make decisions?
The choice of applications, or software, and the way in which applications interact are important elements in making data available and useful.
-
Reading: Scenario, Nyasha at Meramita Hospital (15 minutes)
Nyasha is a patient enrolled in HIV care at the Meramita Hospital. Every six months, Nyasha comes to the hospital’s HIV clinic for a regular visit to check her viral load and have a thorough exam.

The nurse assistant gathers the following information: Nyasha’s weight, blood pressure, and other vital signs. The clinician notes symptoms and other observations from the physical exam.
Upon physical exam, the clinician has noticed signs of possible TB infection and so sends Nyasha to the radiology department along with an order for a chest x-ray. The radiologist must send the x–ray results back to the clinician.
Nyasha’s provider also sends an order to the lab for a viral load count. The lab technician receives the order and must transmit the viral load results back to the clinician.
At the end of her visit, Nyasha gets a prescription that she must get filled at the pharmacy. The pharmacy charges a small fee for this month’s supply of medication.
- What information must be recorded during this visit to Meramita Hospital?
- Where will all this data be recorded?
-
Reading: Can One System Do Everything? (5 min)
While it may appear to be convenient to have one system that can fulfill all of the functions just described, the complexity of such a system has drawbacks. It takes longer to develop a system that addresses a wide variety of needs, rather than specializing in needs specific to one area, e.g. laboratory services, and the complexity of such a system makes it harder to diagnose and resolve problems.
Having a separate system specialized in its area makes it much easier to optimize the functionality serving that area. Specialization, in other words, allows a system to do what it does best.
To achieve the same ends as a single system that does everything, interoperability, or the ability of different systems to interact and share information, becomes important.
-
Reading: Where is data stored and used? (5 min)
Earlier we mentioned three audiences that use data to make decisions:
- Care providers/clinicians: use data such as vital signs, symptoms, physical observations, and test results to decide how to treat a patient.
- Program managers: including facility managers and supervisors, use data such as clinic attendance rates, immunization rates, and supply usage to make decisions about things like staffing, outreach activities, and supply orders.
- Policy-makers: including surveillance officers at the regional or national level, use data (usually aggregate data) such as disease prevalence or treatment failure rates to make decisions about policy, like epidemic response, allocation of resources, or revisions to treatment guidelines.
When designing a health information system, we need to take into account where, when, and how decision-makers will access the information.
-
Reading: System Architecture (5 min)
In the module on System Classification, we looked at the logic underlying information systems, the logic model, and how to classify or describe different elements of a system. We’ve just discussed how a health information system can be made up of many component systems. We also looked at how health information must be accessed at many different levels in order to be used to improve health care service provision. Now let’s look at how all of this comes together through systems architecture.
-
Reading: Architecture (5 min)
When you hear the word “architecture,” you probably think of an architect, a person who designs houses or buildings. An architect develops a blueprint that shows what and where different rooms in a house will be or what it will look like. In addition, their blueprint must contain fundamental elements that will allow the house to be built, including several key systems - like plumbing and heating systems.

Just like an architect must include a variety of systems into their blueprint for a house, those designing a health information system must come up with a blueprint for a health information system that includes all necessary components and respects certain principles.
Health information system architecture describes the fundamental organization of the system embodied in its components, standards, and principles governing its design and evaluation.
This builds on the underlying logic of all systems. Remember the logic model? In doing so, multiple systems can be aligned with a shared outcome for a health information system. Because inputs like social, legislative/regulatory, and physical contexts are considered, a health information system architecture can guide the design and selection of systems, and govern how they interact. This can result in a health information system that is flexible, works in a country’s context, and reduces duplication.
-
Reading: Four Types of Architectures (20 min)
Let’s look at four types of architectures—stand-alone, centralized, decentralized, and federated—that show different ways of organizing the relationships between components, technology and data.
Instructions: Click or tap the four buttons below to learn more about each type of architecture and the advantages and limitations for each one.
Stand-Alone System
Let’s start with a simple systems architecture: the stand-alone system. A stand-alone system is usually limited to one context: one clinic, or one hospital department like the lab or maternity. This type of system is not connected to other systems. The information stays in that system and doesn’t move.

A clinic needs power in an area with an unreliable electricity grid. You decide to install a solar panel. This solves the problem: it provides power for the clinic, regardless of the main grid. Each clinic in the catchment area gets its own solar panel—its own stand-alone system. However, if you need to know when the power is out at a particular clinic, you have no way of knowing unless you go to that clinic. The solar panels have no way of communicating their status to you at the central level.
An Access database to track medical equipment is another example of a stand-alone system. It contains all the data necessary to effectively log inventory and maintenance, but when the equipment manager needs to share data with the district Health authority, they must take the data, export it to a spreadsheet or other form and then email that form to the district.
In Cote d’Ivoire, the Ministry of Health is implementing the Basic Laboratory Information System (BLIS) in general hospital laboratories using a stand-alone system. Each hospital has its own database with all the lab information. Reports can be printed from BLIS and emailed to the Ministry of Health and other stakeholders.
Advantages and Limitations:
The stand-alone architecture’s simplicity makes it easier to troubleshoot when the user or system runs into difficulty. However, sharing information between actors within a facility—such as relaying lab results to the primary care provider—or across reporting levels—such as aggregating data from multiple clinics— is difficult. A stand-alone system generally means that information sharing must take place externally to the system.Centralized System
Centralized systems have a single database. This database may also be known as a central repository or warehouse that contains all the entered data, no matter where it is entered. You can have a single data entry point or many, within a single facility or multiple facilities. There is one place where all of the data is kept.
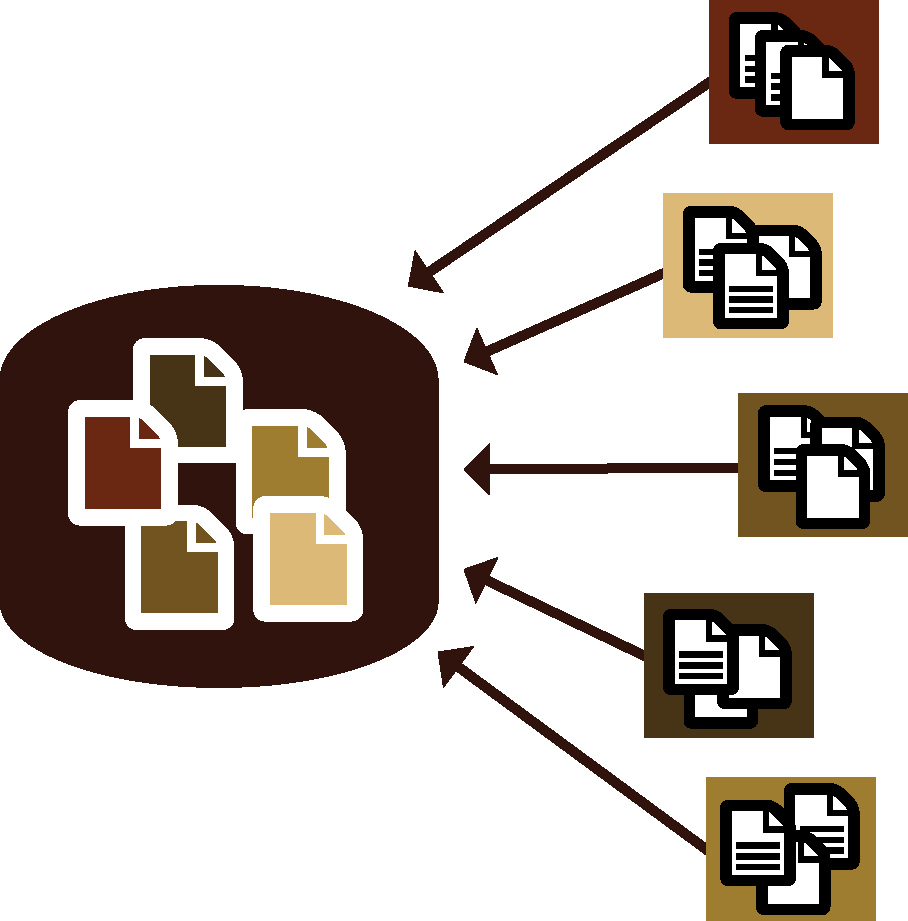
The cloud is often used to house a centralized repository for data that can be entered from any internet-connected point.
For example, DHIS2 is commonly set up where summary data from multiple facilities are entered into a district level database. There are no local databases and users sign into the single, district level system. The DHIS2 database centralizes the aggregate information from many facilities.
Another example is a hospital with a multi-departmental electronic medical record system. No matter where the patient is being treated in the hospital— inpatient ward, maternity ward, surgery— the provider can access the EMR and enter data for that patient. A community health outreach mobile deployment is yet another illustration of a centralized system: each phone is a “node,” or data entry point, but information entered by each community health worker ends up in the same repository by syncing (sending its information) to a central server. The centralized system is distinguished from the stand-alone system by its connectivity.
Advantages and Limitations:
This architecture makes accessing data from multiple places much easier. It can be created easily because you implement the same thing everywhere. It does, however, require substantial technological infrastructure and policy framework to support communication between the data entry point and the central repository, and to ensure the security of the information as it passes between units. If the central repository breaks down, the entire system is unusable.De-centralized System
Let’s look at an example that is a little more complex: the de-centralized system. Unlike a centralized information system architecture, a de-centralized system architecture can have multiple databases or repositories that collect data from many sources. It is usually accessed by the user through one entry screen. For example, DHIS2 has been implemented in Pakistan using a de-centralized model, where users enter data from multiple facilities into multiple databases. These databases are accessed by stakeholders.
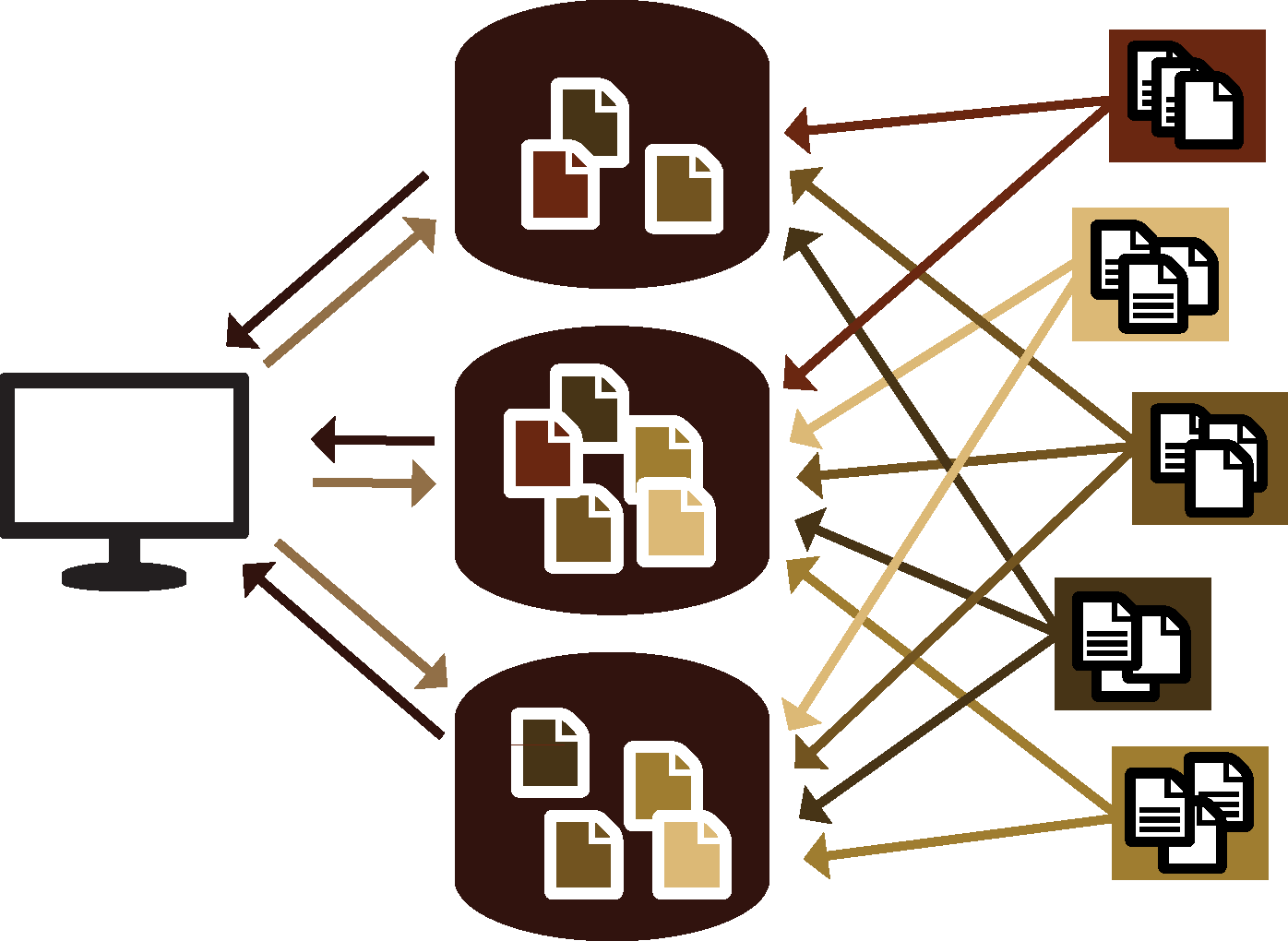
Advantages and Limitations:
Depending on how access is managed, this architecture can ensure wide accessibility, or limit information to certain actors or levels. The infrastructure needs vary widely, as well. Strong security measures and protocols are necessary to protect the information.Federated System
A federated system architecture brings data and information from individual systems into a shared data warehouse. The centralized repository often receives only a subset of the data available in each system’s repository. In a way, a federated system is therefore a blend of centralized and de-centralized systems.
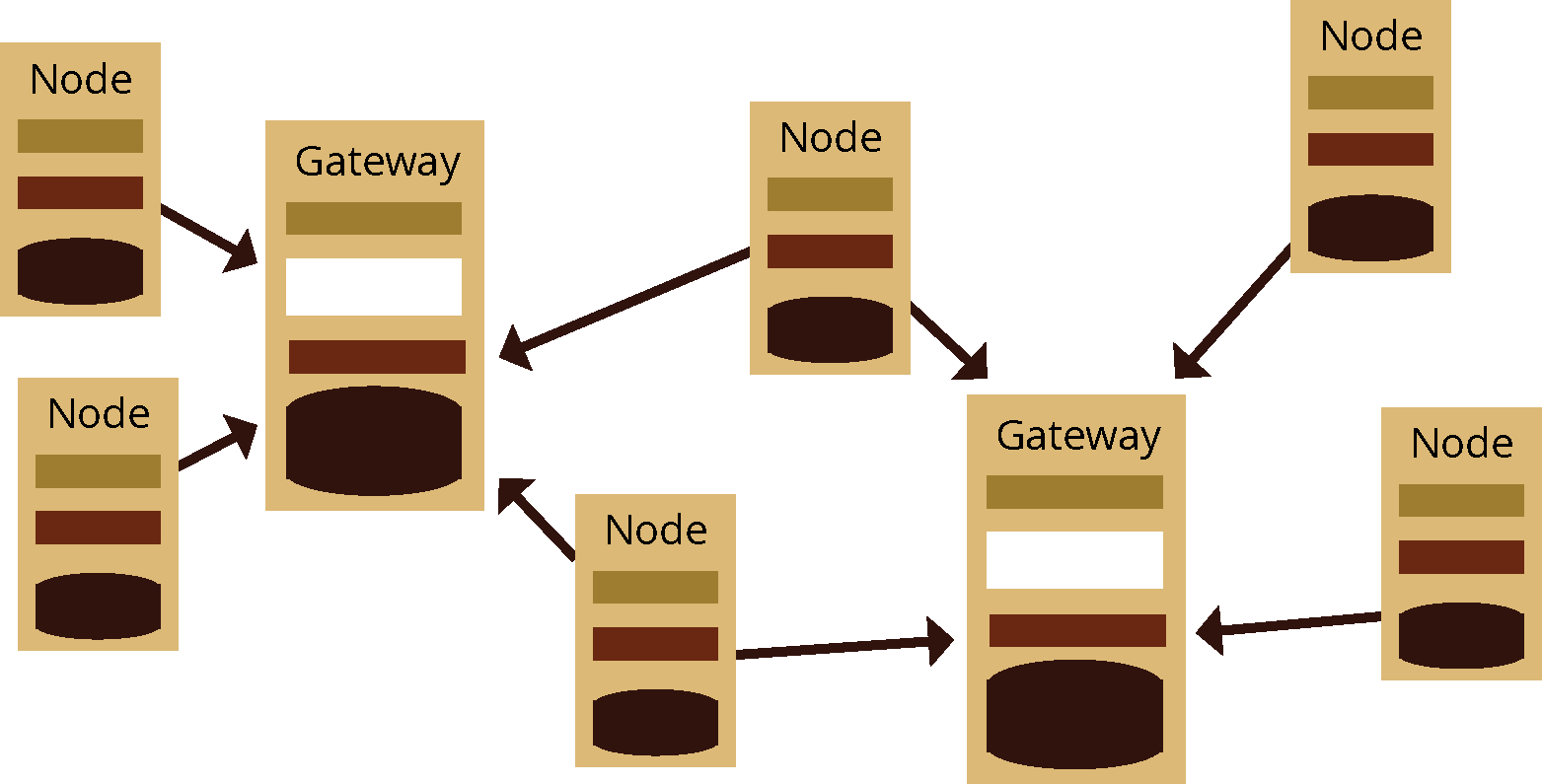
For example, NGO Alpha has 15 clinics that run on System A. NGO Beta has 100 clinics that run on System B. Both Alpha and Beta must report some of their data to the national system, NatDat. System A and System B connect with NatDat to automatically send the required data on a regular basis. The NGOs have ownership of their systems and their data, but share required data with the national level, like sending standard reports to DHIS2.
In another application of a federated architecture, an electronic medical record system in Haiti has been set up to replicate local databases to a consolidated database housed at the national level and in the cloud.
Advantages and Limitations:
Federated architecture involves multiple actors, each with their own goals, needs, and structure. With this architecture, each actor can share core information and address their individual needs without losing their autonomy.It is important to clarify who owns the data in this type of architecture. Clearly defining standards of integration—e.g., making sure that everyone reports the same thing accurately—is essential.
A federated system may look complicated, but as long as the architecture—including system norms, protocols, rules for data exchange, and security—is robust and well-documented, it can address the requirements of a national-scale health information system.
-
Reading: Advantages of Specialization (5 min)
Looking at systems from an architecture perspective highlight the value in specialization. Each system within the architecture is specialized to do what it does best, be it laboratory information, electronic medical records, x-ray images, or billing.
By linking systems through a formal architecture, rather than developing one system to do everything, there is the ability to modify the components within the architecture in response to changing needs and evolving technology. This includes the ability to:
- Swap components
- Upgrade particular workflows
- Change human behavior slowly, that is, effectively manage change
-
Reading: Putting It All Together - Architecture (15 min)
We’ve just seen four types of architecture, each with advantages and limitations. Let us now return to our house architect. When building a house, you often start with a bare plot of land. However, when building a health information architecture, you rarely begin with a blank slate. There are often existing systems, implemented on small scales or in specific regions, or dealing with specific issues, such as a vaccine registry, or a community health survey application, or a local laboratory system. It’s like having a compound with a small house and a few sheds and buildings, and needing to renovate it all into a big, new house for your growing family.
How do you know what to keep? What to get rid of? What to improve or upgrade? What do you need to build from scratch?
When assessing or developing a system architecture, it is important to ask questions about the current status of systems and where you want the HIS to be in the future.
What systems are in place right now? How do they communicate (or not)?
For example, if a system is stand-alone, can it be modified to communicate with other systems in a federated architecture? Should it instead be replaced by a system that already has communication built in? What makes the most sense from a cost perspective? What is the time frame for each option? What other resources, including training for users must be considered for each option?
-
Quiz: Knowledge Check (5 min)
Assess your knowledge about the concepts you learned so far on architecture by answering two questions, which will help you put it all together.
Instructions: Click or tap the correct answer, then tap the Feedback button to reveal the correct answers and additional information
-
Reading: Considering Different Architectures (5 min)
As the group considers different architectures in more detail, they will need to answer some key questions.
- What data from the county system are needed at the district, regional, and national levels?
- What facility-level information systems collect this data?
- Is it better to have a single repository or multiple hubs?
- Are these systems able to exchange data? For instance, can the laboratory information system share data with the electronic medical record system?
- How will the facility level system exchange data with the district, regional, and national levels? Does the Ayo County system need to be upgraded or totally replaced?
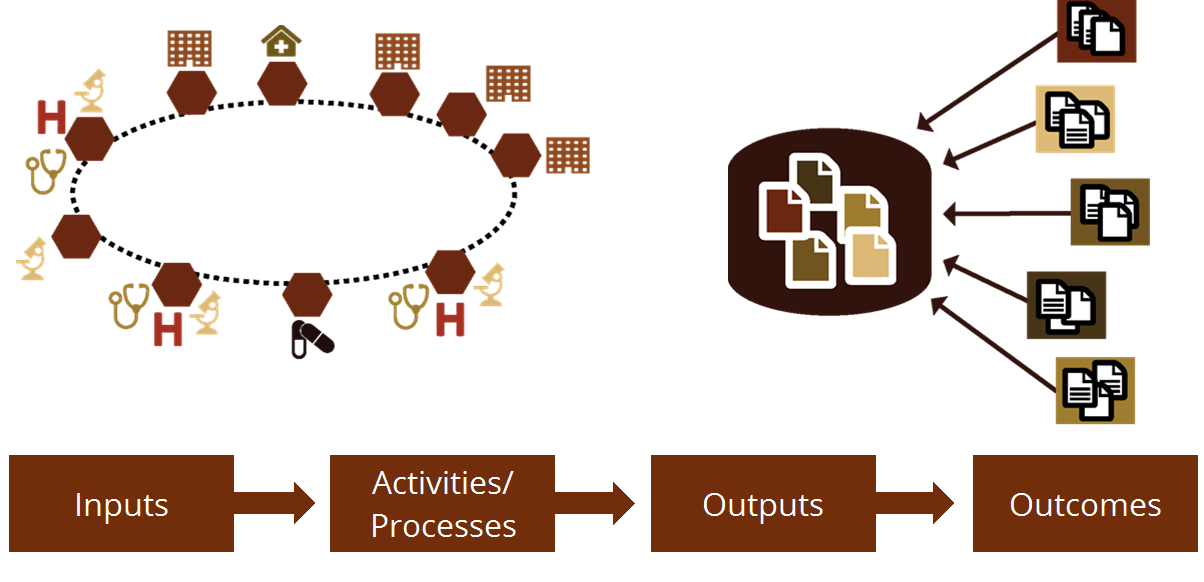
Answering these questions will help the group further describe the systems that will work most effectively in their overall health information system. This allows the group to provide guidance on key health information system inputs — standards, policies, procedures, system selection — that will harmonize health information system activities, leading to better information system outputs and outcomes.
At the national level, the HIS technical working group must use their knowledge of the country’s context, the overall health information system, system classifications, and system architecture to determine which applications would be used and how they will interact.
-
Self-Reflection: System Architecture (15 min)
Take a moment to reflect on what you’ve learned in this module. You may find it helpful to write down your responses in your journal.
- What type of architecture would you recommend to Dr. Obuso’s working group?
- What further information would you need before you make a decision?
-
Reading: Summary (5 min)
Congratulations! You just completed this module. You’ve just learned about four different kinds of system architecture: stand-alone, centralized, decentralized, and federated architecture. Now go on to the final quiz.