Data Collection & Documentation
Complete Inventory of Unique Attributes
When new data is receieved from a producer, all attributes in every source file are documented. Metadata provided with the data is the primary reference. If no metadata is provided, educated decisions based on online records, other available documentation, and phone calls and emails to the data producers are used.
Standardized Attributes
Each data producer collects and maintains different sets of attributes in their parcel and assessor data, as determined by business needs and available resources. Washington State also requires counties to collect and maintain certain data.
The different sets of attributes from different producers often overlap with one another (for instance, all counties maintain land use information for each property), but different data producers may provide identical attributes in different formats or under different names. Some attributes are only provided by one or two data producers.
During initial development of the 2007 database, an exhaustive study of every attribute provided by every data producer, was undertaken to determine what attributes were common across producers. In this way a set of standardized, common, parcel data attributes was developed.
This list of common attributes was refined into the final list of normalized attributes through a data use survey, asking members of the Parcels Working Group to identify what attributes they required in parcel data. Additionally, any common attribute that was provided by 80% of the data producers, and all market and taxable value attributes were included. Review of the initial database by users, as well as attempts to better align the database with FGDC Cadastral Subcommittee parcel data standards led to revision of the normalized database attribute list.
The data not only varies from producer to producer, but the source data files, data formats, attributes provided, and data quality vary for each producer from version to version of the database. As a general rule, data quality and availabilty are improving over time.
| database version | number of tables provided | number of attributes provided | number of common attributes provided | number of common attributes normalized |
|---|---|---|---|---|
| 2007 | 66 | 1914 | 140 | 39 |
| 2009 | 90 | 2420 | 144 | 53 |
| 2010 | 146 | 4510 | 282 | 70 |
| 2012 | 151 | 4877 | 293 | 71 |
Determining Database Structure
The Database structure needed to be able to handle all of the normalized attributes and the complications they present, such as multiple owners/taxpayers for a parcel, or an owner owning multiple parcels. A relational database structure was selected as the most appropriate way to handle our needs. It was important that this structure be flexible to changing needs and capabilities in the future.
Database Schema
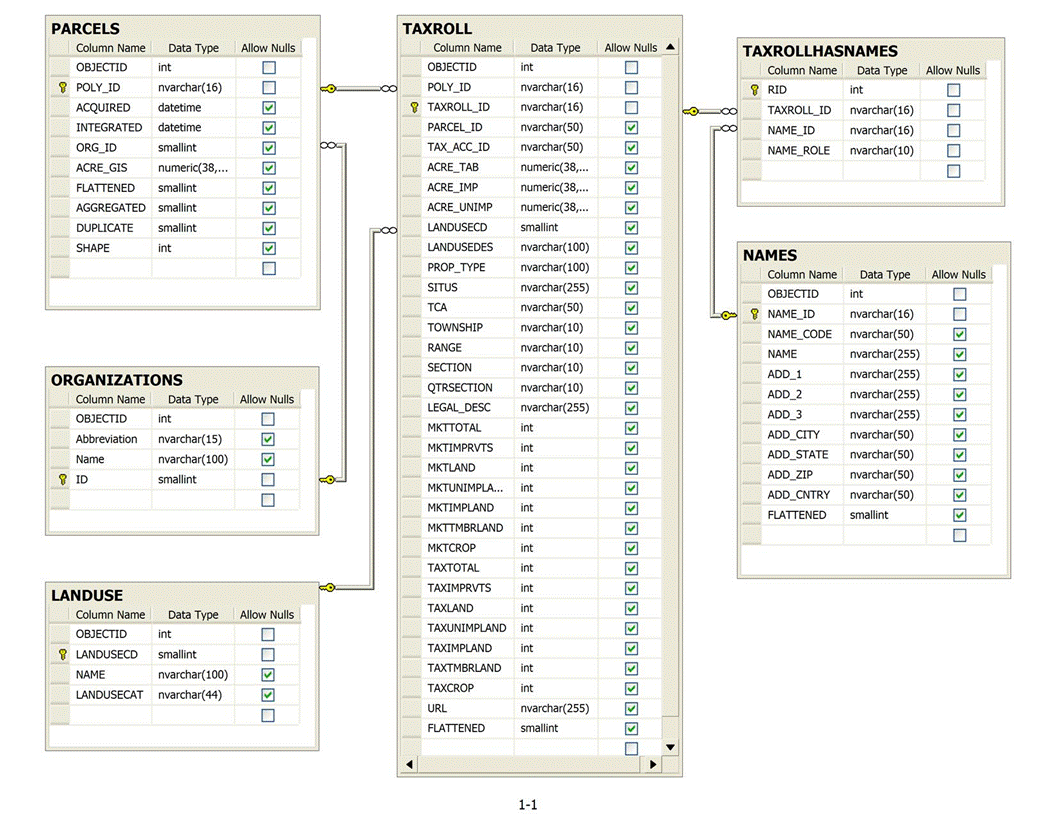
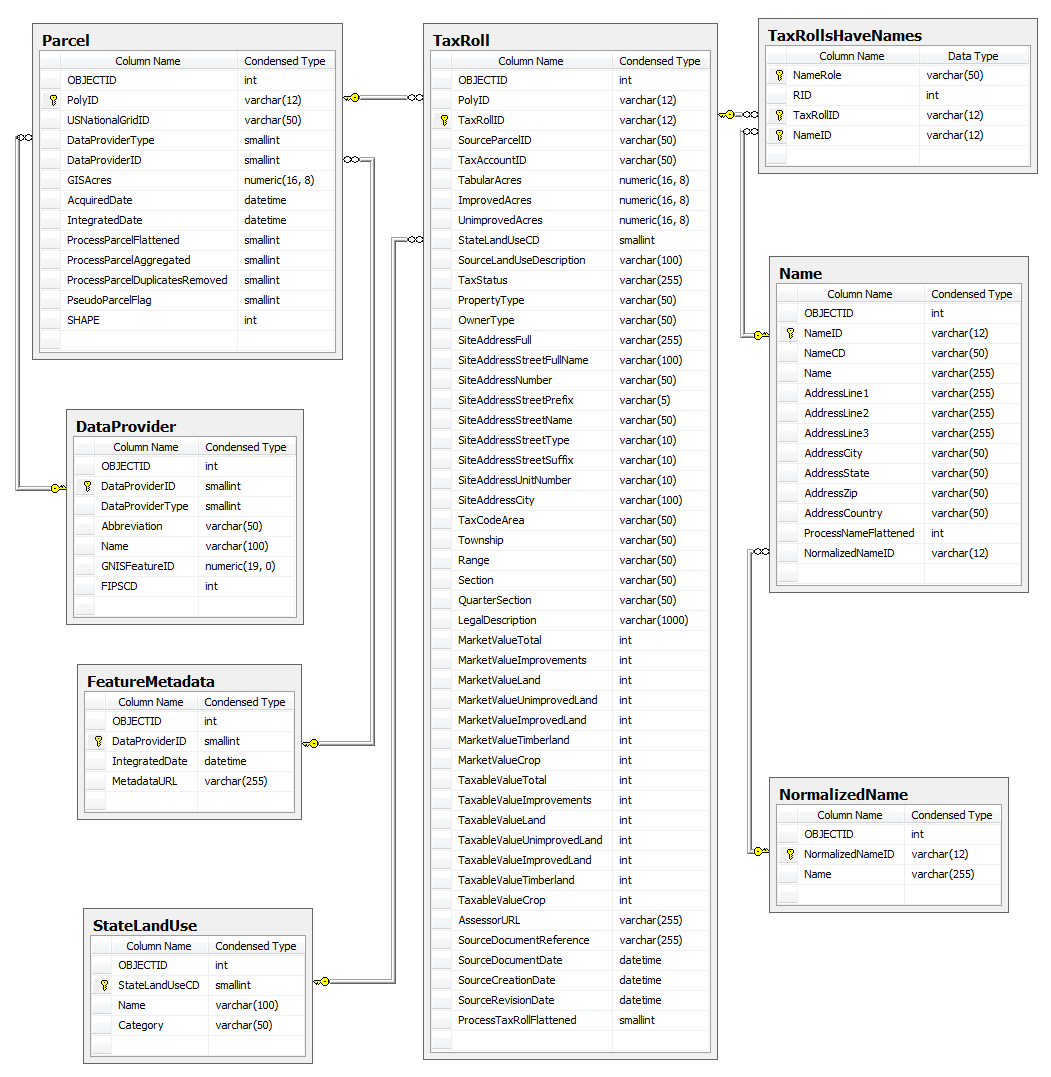
Below are the database entity relationship diagrams (ERDs) for each version of the database. They show how the multiple database tables relate to one another, what attributes are present in each table, and how the database structure has changed between versions. Click on the links to see the full size ERDs.
| Entity Relationship Diagrams | |
| 2007 | ERD.gif |
| 2009 | ERD.png |
| 2010/2012 | ERD.png |
{kind=link}
{kind=link}
{kind=link}
Normalized Attributes
A list of attributes that were normalized into the Washington State Parcel Database can be found on the normalized attributes page. The normalized attributes for each version of the database can also be seen in the database entity relationship diagrams (ERDs) above.
Normalization Process
Washington's counties and other data producers each provided data with a unique combination of format, attributes, and structure. Transforming these data into the Washington State Parcel Database required a tool capable of processing data in all of these formats. Safe Software's Feature Manipulation Engine (FME) was the software selected. An FME process (workspace) was created for each data producer which read in the original data in whatever form it was delivered; renamed, added, removed, and modified attributes as needed; and wrote records into the multiple related tables of our SQL Server/ArcSDE Database. The image below is a simplified, hypothetical, FME workspace example.
 |
Breadcumbs
We wanted to ensure that anyone using the database understood what processing steps were taken to normalize the data. There are five attributes we added counting the number of times we did some sort of spatial or tabular processing.
There were two tabular process run, one on the Name information and one on the Taxroll information for each county. These processes removed duplicate, identical Name and Taxroll records from the database. For example if one person owned four parcels, rather than having their name information in the Database four times, it only occurs once, but the attribute ProcessNameFlattened in the Names table would have a value of 4. The TaxRoll table uses the field ProcessTaxRollFlattend.
There were three spatial processes run on the parcel data.
- Duplicate parcels were identified and removed, and the ProcessParcelDuplicatesRemoved value in the Parcel table set to the number of occurances of a parcel in the original data. A NULL value indicates that there were no duplicates.
- Parcels with identical geometry, but different attributes did not need to have the geometry repeated in the Parcel table, but the different attributes needed to be maintained in the Name and TaxRoll tables. These parcels were identified and the ProcessParcelFlattened value in the Parcel table was set to the number of times this occurred for each parcel
- Two or more parcels that share identical tax roll information, are in actuality a single parcel, but are represented using multiple geometries in the original data. The parcel geometries were combined into a multi-part polygon, the duplicate tax roll information was removed, and the ProcessParcelAggregated value in the Parcel table was set to the number of original parcels that became the multi-part polygon.
 |
Hardware & Software
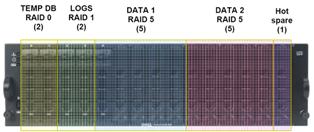
Data is stored in an ArcSDE 9.3 Enterprise Advanced Geodatabase implemented on a SQL Server 2008 Standard Edition platform.
- Database head node
- Dell PowerEdge 1950
- dual Quad-Core Intel Xeon Processors 5450 series processors at 3.00GHz
- eight 2GB DIMMs for a total of 16GB of RAM
- dual mirrored 3.5" 15k rpm 73GB SAS drives for the OS
- PERC 6/E RAID card for database disk array control
- Database disk array
- Dell PowerValut MD1000
- fifteen Serial Attached SCSI (SAS) 15k rpm 146GB drives
The SQL Server database is setup across multiple volumes to match processor sockets and cores for maximum performance.