
About
Experiments that use computational resources are often intrinsically tied to the software development lifecycle. In simulation, experiment results feed into this cycle, informing evolution of the simulation software. Over the course of several of these cycles, several result sets may be generated from various simulation models. Result comparison between different software and simulation models ultimately informs the research design. These comparisons answer the question, “What parameter, or part of our technique, produced this change in the result?” However, it can be especially difficult to keep track of the model, input, or version of the simulation software that produced a given result. Data provenance techniques can connect output and input to analysis software. However, techniques are lacking that connect co-occurring changes in simulation software and models with such changes in simulation input and output.
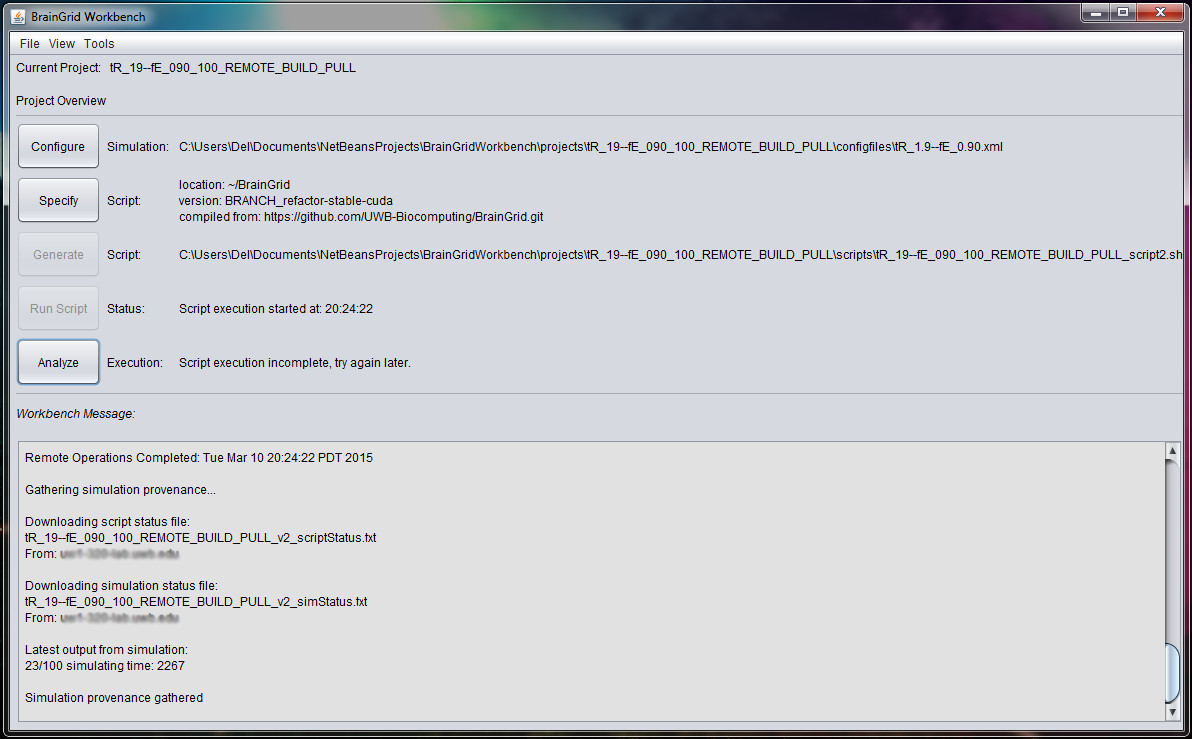
The BrainGrid Workbench is a project management tool for high-performance neural network simulations that allows researchers to explicitly collect simulation and model provenance with respect to source code revision. The source code for the simulator represents part of the overall simulation model that contributed to the specific simulation output. By leveraging the git API, we can determine the version of the source code used to build the simulator. Later, when simulation results are produced, they are linked to the simulator executable, and in turn, to the version of the source code used to build the executable file. Such provenance information is persisted to Turtle files in the form of RDF. Relationships between data are described using the Prov Ontology. Meanwhile, project information is stored in XML format. By using both media together, the BrainGrid Workbench generates introspective simulation detail, informing development on long-running projects.
Currently, BrainGrid Workbench can support individual projects into the output phase. We would like to connect such provenance to that which describes the analysis phase. An approach to attain such support includes integrating provenance wrappers for Matlab and other analysis tools, such as R. The analysis phase may include comparison of data from various steps in a single project. Meanwhile, simulations may take days or weeks to run. To support analysis that encompasses multiple stages of simulation evolution, the Workbench will also require supplementary version support built into the UI.
For students interested in helping with this project, note that we use the following technologies: Java Swing (moving to FX), Bash Scripting, Make, GIT, and JSch. For more information, please contact Del Davis and Michael Stiber.
Reference:
Michael Stiber, Fumitaka Kawasaki, Delmar Davis, Hazeline Asuncion, Jewel Lee, Destiny Boyer. BrainGrid+Workbench: High-Performance/High-Quality Neural Simulation, In International Joint Conference in Neural Networks (IJCNN), May 2017.
![]()
This work is based upon work supported by the US National Science Foundation under Grant No. ACI 1350724 & CCF 1218266. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the NSF.