
About
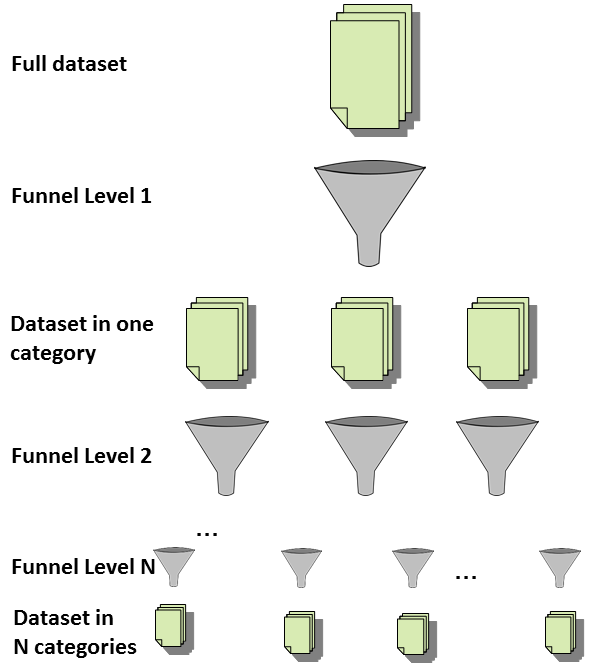
This project revolves around trying to piece together information that has had its provenance lost. It focuses on two primary sets of data.
- Human Generated Data: This process tries to restore the relationship between Wiki news articles, and their respected sources. The analysis is based on the content of the articles themselves, and the articles have any information stripped that links to the source pages, leaving us with the story content itself. The goal is to restore as many relationships as possible using methods like Topic Modeling, Stemming, and Least Common Subsequence.
- Machine Generated Data: The machine set aims to restore the file relationships from Git repositories. An entire repository is scraped to gather every variation of a file that has ever existed, the file names are randomized, and a groundtruth is generated showing how each file was changed over its lifetime in TURTLE format. The aim of this set is to connect the file with the previous versions of a file (i.e. file1.txt would properly be connected with file1.txt from a previous commit).
Both sets are given a groundtruth file, which has the original relationships between files. During the process, we create a graph of computed relationships, we then compare this with the groundtruth to produce precision & recall numbers. This project is based on a challenge that was issued to the provenance community, which you can read more about here.
For students who are interested in this project, we use the following technologies:
- Stemming – The process of finding the root of a word. Used in pre-processing the data for topic modeling
- Longest Common Sequence – to identify the relationship between two files based on common strings
- Topic modelling – Latent Dirichlet Association to cluster documents based on the semantic meaning. 2 tools CVB0, mallet
- Genetic Algorithm – natural evolution technique to optimize topic modelling and avoid providing number of topics and number of iterations
Publications
Subha Vasudevan, William Pfeffer, Delmar Davis, Hazeline Asuncion. Improving Data Provenance Reconstruction via aMulti-Level Funneling Approach, In the 12th International Conference on eScience, to appear.
Subha Vasudevan. Optimized Provenance Reconstruction Using Genetic Algorithm, In the Grace Hopper Celebration of Women in Computing, General Poster Session, to appear.
Ailifan Aierken, Delmar B. Davis, Qi Zhang, Kriti Gupta, Alex Wong, Hazeline U. Asuncion. A Multi-Level Funneling Approach to Data Provenance Reconstruction. e-Science Workshop of Works in Progress, October 2014.
Links
Provenance Reconstruction Challenge
Presentation at IPAW 2014
![]()
This work is based upon work supported by the US National Science Foundation under Grant No. ACI 1350724. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the NSF.