ARTool Align-and-rank data for nonparametric factorial ANOVA
Jacob O. Wobbrock, University of Washington†[contact]
Lisa A. Elkin, University of Washington‡
James J. Higgins, Kansas State University
Leah Findlater, University of Washington
Darren Gergle, Northwestern University
Matthew Kay, Northwestern University‡
Please cite the first paper when using ARTool to examine main effects and interactions.
Please cite the second paper when using ARTool to conduct ART-C post hoc pairwise comparisons.
We also include references to the [R] package "ARTool" and its two vignettes.
Kay, M., Elkin, L.A., Higgins, J.J. and Wobbrock, J.O. (2021).
ARTool: Aligned rank transform.
[R] package with documentation and two vignettes.
Initially published on CRAN October 13, 2021.
Kay, M., Elkin, L.A. and Wobbrock, J.O. (2021).
Contrast tests with ART.
ARTool [R] package vignette. Updated October 12, 2021.
Kay, M. (2021).
Effect sizes with ART.
ARTool [R] package vignette. Updated October 12, 2021.
Coursera Video
The Aligned Rank Transform (ART) is covered in Prof. Wobbrock's
Coursera course on practical statistics.
See the course video
that covers this procedure.
Purpose of the Aligned Rank Transform (ART)
Classic nonparametric statistical tests—the Kruskal-Wallis test, Mann-Whitney U test,
Friedman test, or Wilcoxon signed-rank test—all are one-way tests, permitting the analysis of only
a single factor at a time. As a result, multi-factor designs cannot be analyzed with these straightforward
rank-based tests. Furthermore, the simple rank transform procedure (RT) of Conover and Iman (1981),
which uses an ANOVA on midranks, is reasonable for main effects but causes inflated Type I errors for
interaction effects (Salter & Fawcett 1993; Higgins & Tashtoush 1994). Thus, something besides a simple
RT procedure is necessary if we are to analyze multiple factors nonparametrically.
But wait—isn't there a nonparametric equivalent to the factorial ANOVA? Surely there must
be! Surprisingly, there is no real consensus on such an analysis. Although there has been work by researchers
on nonparametric factorial analyses, the resultant methods remain relatively obscure.
For a review of some methods, see, e.g., Sawilowsky (1990).
To illustrate the point, consider this
table of analyses
from UCLA; you will see that no entry is given for two or more independent variables with
dependent groups (i.e., repeated measures). A parametric analysis would be, of course, the repeated
measures ANOVA, but an equivalent nonparametric analysis is not provided.
The Aligned Rank Transform (ART) procedure was devised to fill this gap (Fawcett & Salter 1984;
Higgins et al. 1990; Higgins & Tashtoush 1994; Salter & Fawcett 1985; Salter & Fawcett 1995).
For each possible main effect or interaction, all responses (Y) are first "aligned" (Hodges & Lehmann 1962),
a process that strips from Y all effects but the one for which the alignment is being carried out. Let an aligned
response be Yaligned. The aligned response Yaligned is then assigned midranks;
let this ranked response be Yart.
Then a factorial ANOVA can be run on Yart, the aligned-and-ranked responses; vitally,
unlike when using the regular rank transform (RT), using an aligned rank transform (ART) ensures that main effects
and interactions have appropriate Type I error rates and suitable power.
So why make and publish ARTool (Wobbrock et al. 2011)? ARTool creates, for each possible main effect or interaction, one new aligned column
(Yaligned) and one new ranked column (Yart). (Doing so by hand would be
extremely tedious and error-prone.) In general, for N factors, ARTool produces 2N-1
aligned columns and 2N-1 ranked columns. You can then analyze the Yart responses
with your favorite statistics software.
Importantly, when a facorial ANOVA is run on any given Yart response, only the effect for
which Y was aligned and ranked can be extracted from the ANOVA table. The other table entries are meaningless.
Thus, for each main effect or interaction in the statistical model, a separate full-factorial ANOVA must be run
using a different Yart response.
Example:
You have a continuous response Y and two factors, X1 and X2. Using ARTool, you create three aligned
responses, Yaligned for X1, Yaligned for X2, and Yaligned
for X1×X2. Then these three columns are each ranked by ARTool, resulting in three
additional columns: Yart for X1, Yart for X2, and
Yart for X1×X2. Then you run three separate full-factorial ANOVAs.
The first ANOVA has Yart for X1 as the response, so in the ANOVA table, you only regard
the main effect of X1. The second ANOVA has Yart for X2 as the response,
so in the ANOVA table, you only regard the main effect of X2. The third ANOVA has
Yart for X1×X2 as the response, so in the ANOVA table, you only
regard the X1×X2 interaction. In all three ANOVAs, the model factors are
X1, X2, and X1×X2.
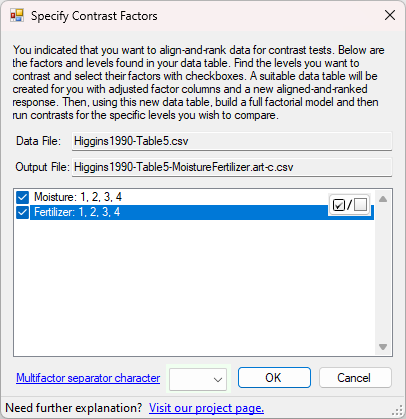
In our most recent work, we have extended the ART procedure with an additional procedure we refer to as ART-C
(Elkin et al. 2021).
ART-C is an additional align-and-rank procedure to facilitate post hoc pairwise comparisons. As it turns
out, you cannot use regular Yart responses for post hoc pairwise comparisons without
inflating Type I error rates. The ART-C procedure allows you to indicate which factor(s) have levels that you
would like to compare directly, and ARTool creates additional aligned-and-ranked responses precisely for those
comparisons.
Example:
You have a continuous response Y and three factors, X1, X2, and X3.
Each of these factors has two levels, with X1={a, b}, X2={c, d}, and X3={e, f}.
So, your study employs a 2×2×2 factorial design. Using ARTool, you discover a significant
X1×X2 interaction. You also discover that X3 is non-significant, either alone
or in any interactions. Therefore, you wish to compare levels from X1 and X2 (e.g.,
conditions {a,c} vs. {b,d}). To do this, you use ARTool's new contrasts
feature and indicate X1 and X2 as the contrast factors. ARTool produces a second data table
for you with two factors. The first factor we'll call X12, a single "concatenated factor" whose levels are
concatenated from those of X1 and X2: {ac, ad, bc, bd}. The second factor is X3, unchanged
from its original levels {e, f}, because it was not indicated as a contrast factor. The new response column is
Yart-c for X12. Now, in your favorite statistics software,
you run a full-factorial model on Yart-c for X12
with factors X12, X3, and X12×X3. You ignore the omnibus test results
but, within this model, you request the post hoc pairwise
comparisons you desire within X12. For example, to compare {a, c} vs. {b, d}, you
compare X12's levels "ac" and "bd". This test will have appropriate Type I errors and
power. Of course, if you conduct multiple such comparisons, you should apply a correction, e.g., Holm's
sequential Bonferroni procedure (Holm 1979).
Using ARTool.EXE on Windows
Most modern statistics software tools lack built-in features for aligning data. Aligning data is extremely tedious
and error-prone to do by hand, especially when more than two factors are involved. That is why we created
ARTool.EXE — to do the aligning and ranking for you. This program is downloadable
from this page and runs only on Microsoft Windows.
ARTool takes a character-delimited CSV file as input (*.csv). ARTool can work with any text character as a delimiter,
or a space or a tab. It can also employ different delimiters for reading in and writing out data tables.
The default delimiter is a comma, but European number formats can be handled by telling ARTool to use
a delimiter other than a comma (e.g., a semicolon) and to treat commas as decimal points.
The file read in by ARTool must represent
a long-format data table (one response Y per row, in the right-most column). The first row
must be delimited column names. The first column must be the experimental unit, e.g., Subject.
This column, which we'll call S, is not used in ARTool's mathematical calculations, but
is useful for clarity in the output table, and is essential anyway for long-format repeated measures
tables where the same experimental unit must be listed in multiple rows. As noted, the last column
must be the numeric response (Y), i.e., dependent variable.
Each column between S and Y represents one factor (X1, X2, X3, etc.)
from the experiment. Each possible main effect and interaction results in a new aligned column and a
new ranked column in the output CSV file written by ARTool.
The alignment process used is that for a completely randomized design. This can
result in reduced power for other designs like split-plots, as described by
Higgins et al. (1990). But this is the simplest and most easily generalized alignment algorithm
to implement. As it may only reduce power, any significant results should be trustworthy.
For more on this issue, see Higgins et al. (1990) and Higgins & Tashtoush (1994).
The output of ARTool for main effects and interactions is a new CSV file, by default with extension *.art.csv.
This new file will have, for each effect, an "aligned" column showing the aligned
data (Yaligned), and an ART column (Yart) showing midranks applied
to the corresponding aligned column. As the original table's columns are also retained, the output data table will have,
for N factors, (2+N) + 2*(2N-1) columns. Thus, if the original table has 2 factors,
the output table will have (2+2) + 2*(22 - 1) = 10 columns. If the original table has 3 factors,
the output table will have (2+3) + 2*(23 - 1) = 19 columns.
The output of ARTool for optional ART-C contrast tests is another CSV file, by default with extension *.art-c.csv.
It will contain a new "concatenated factor" combining all of the requested contrast factors. It will also retain,
unchanged, any other factors from the original data table not requested for contrasts. It will have one aligned
column (Yaligned for ...) and one ranked column (Yart-c for ...).
ARTool performs various checks to ensure its alignment and ranking procedures execute correctly.
One important check ensures that each aligned column sums to zero. Users of ARTool can perform a further sanity check
by running a full-factorial ANOVA with each aligned column as a response. All effects other than the one
for which the column was aligned should be close to F=0.00 and p=1.00.
The CSV files written by ARTool can be opened directly in Microsoft Excel. Statistics software can also open
CSV files. There, you can run your ANOVA analyses on the aligned-and-ranked columns.
Using ARTool in [R]
If you use the [R] version of ARTool,
things are somewhat streamlined. The art() function performs all of the alignment and ranking that
Windows ARTool does, but also runs multiple ANOVAs for you behind the scenes — extracting the appropriate result
from each ANOVA — and assembling one final ANOVA table for you. Similarly, the art.con() function,
which runs the ART-C procedure, also performs the alignment and ranking steps like Windows ARTool does, but
additionally runs all requested pairwise comparisons, applying any indicated adjustment (e.g., "tukey", "holm",
"bonferroni", "none", etc.). Below, we offer sample code for using ARTool in [R].
The ARTool package is available on CRAN.
The source code for the package is available on Github.
You can install the latest CRAN version with this command, which you only need to do once:
# download and install the ARTool package
install.packages("ARTool")
Using the ARTool package, the ART procedure is run on a long-format data table in CSV format
using the following code:
# load the ARTool library into memory
library(ARTool)
# read a data table into variable 'df'
df <- read.csv("mydata.csv") # assumes file is in working directory# assume 'S' is the name of a within-subjects column
# assume 'X1' is the name of the first factor column
# assume 'X2' is the name of the second factor column
# assume 'X3' is the name of the third factor column
# assume 'Y' is the name of the response column
# run the ART procedure on 'df'
m = art(Y ~ X1 * X2 * X3 + (1|S), data=df) # linear mixed-model syntax; see lme4::lmer()
anova(m)
For between-subjects data, where each row has a unique subject identier S, omit the random factor:
# omit 'S' for between-subjects data
m = art(Y ~ X1 * X2 * X3, data=df) # linear model syntax; see lm()
anova(m)
Post hoc pairwise comparisons can be conducted using ART-C. In the output above, factors
X1 and X2 show a significant interaction. Let's assume X1 has levels
{a, b} and X2 has levels {c, d}. Code to conduct post hoc pairwise comparisons for
the four conditions formed by X1×X2 is as follows:
library(dplyr) # for %>% pipe
art.con(m, "X1:X2", adjust="holm") %>% # run ART-C for X1×X2
summary() %>% # add significance stars to the output
mutate(sig. = symnum(p.value, corr=FALSE, na=FALSE,
cutpoints = c(0, .001, .01, .05, .10, 1),
symbols = c("***", "**", "*", ".", " ")))
Here is example output:
contrast estimate SE df t.ratio p.value sig.
a,c - a,d -15.00 4.17 18 -3.595 0.0124 *
a,c - b,c -4.75 4.17 18 -1.138 0.8097
a,c - b,d -2.25 4.17 18 -0.539 1.0000
a,d - b,c 10.25 4.17 18 2.456 0.0977 .
a,d - b,d 12.75 4.17 18 3.056 0.0340 *
b,c - b,d 2.50 4.17 18 0.599 1.0000
Results are averaged over the levels of: X3
Degrees-of-freedom method: kenward-roger
P value adjustment: holm method for 6 tests
Thus, in this example, it seems that {a, c} vs. {a, d} and {a, d} vs. {b, d} exhibit the
significant differences within X1×X2.
ART Mathematics
The mathematics for the general ART procedure were
worked out by Higgins & Tashtoush (1994). To the best of our knowledge, the
literature on the ART does not present a general formulation for N factors;
most publications only address two factors.
To enable the creation of ARTool, James J. Higgins worked out the mathematics for
N factors. The steps below are those that ARTool
uses to align and rank data for main effects and interactions.
(You'll see why you wouldn't want to do this by hand!)
Step 1: Residuals. For each raw response Y, compute its residual as
residual = Y - cell mean
The cell mean is the mean response Y̅ for that cell, i.e., over all Y's whose
levels of their factors (Xi's) match that of the Y response for which we're
computing this residual.
Example: The example table below has two
factors (X1, X2), each with two levels {a,b} and {x,y}, and one response column
(Y), and shows the calculation of cell means:
Subject
X1
X2
Y
cell mean
s01
a
x
12
(12+19)/2
s02
a
y
7
(7+16)/2
s03
b
x
14
(14+14)/2
s04
b
y
8
(8+10)/2
s05
a
x
19
(12+19)/2
s06
a
y
16
(7+16)/2
s07
b
x
14
(14+14)/2
s08
b
y
10
(8+10)/2
Step 2: Estimated Effects. Compute the "estimated effects." This is best illustrated with an example.
Let A, B, C, D be factors with levels:
Ai, i = 1...a
Bj, j = 1...b
Ck, k = 1...c
Dℓ, ℓ = 1...d.
Let Ai indicate the mean
response Y̅i only for rows where factor A
is at level i. Let AiBj indicate the mean
response Y̅ij only for rows where factor A is at level i and factor B is at level j.
Let AiBjCk indicate the
mean response Y̅ijk only for rows where factor A is at level i, factor B is at level
j, and factor C is at level k. And so on...
Let μ be the grand mean of Y̅ over all rows.
Main effects
The estimated effect for factor A with response Yi is
= Ai
- μ.
Two-way effects
The estimated effect for the A×B interaction with response Yij is
= AiBj
- Ai - Bj
+ μ.
Three-way effects
The estimated effect for the A×B×C interaction with response Yijk is
= AiBjCk
- AiBj - AiCk - BjCk
+ Ai + Bj + Ck
- μ.
Four-way effects
The estimated effect for the A×B×C×D interaction with response Yijkℓ is
= N way
- Σ(N-1 way)
+ Σ(N-2 way)
- Σ(N-3 way)
+ Σ(N-4 way)
.
.
.
- Σ(N-h way) // if h is odd, or
+ Σ(N-h way) // if h is even
.
.
.
- μ// if N is odd, or
+ μ// if N is even.
Step 3: Alignment. Compute the aligned data point Yaligned corresponding to
the raw data point Y for the effect of interest as:
Yaligned = residual + estimated effect, i.e.,
= result from step (1) + result from step (2).
Step 4: Ranking. Assign midranks to all Yaligned responses for each new
aligned column, thereby creating the Yart columns. With midranks, or averaged ranks,
"if a value is unique, its averaged rank is the same as its rank. If a value occurs k times,
the average rank is computed as the sum of the value's ranks divided by k"
(SAS JMP documentation).
As noted above, ARTool computes aligned data columns (for inspection)
and midranks for each of these columns (for ANOVA).
Step 5: Full Factorial ANOVA. This step is not performed by Windows ARTool,
but is performed by the [R] version of ARTool, which is to conduct full-factorial ANOVAs on the aligned and
ranked responses (Yart). Using the same factors (Xi's)
as model terms, conduct a separate ANOVA for each main effect or interaction, being careful to interpret the
results only for the factor or interaction for which Yart was aligned and ranked.
(Note: Again, if you're using the [R] version of ARTool, it does this for you.)
Example: If you have two factors (X1 and X2), and response (Y), you will
run three ANOVAs, each using the same input model
(X1, X2, X1×X2), but using a different response variable, one for each aligned-and-ranked Y.
That is, one ANOVA will use the response for which Y was aligned-and-ranked for X1.
The second ANOVA will use the response for which Y was aligned-and-ranked
for X2. The third ANOVA will use the response for which Y was aligned-and-ranked for
X1×X2. When interpreting the results in each ANOVA's output,
only look at the main effect or interaction for which Y was aligned-and-ranked. So you would
extract one result from each of three ANOVAs, for three total results.
ART-C: Contrast Tests with ARTool
A procedure for conducting post hoc pairwise comparisons within the ART paradigm, called ART-C,
was devised by Lisa Elkin and Jacob O. Wobbrock (Elkin et al. 2021). This procedure and its mathematics
were validated through extensive simulation studies to ensure that Type I error rates were not inflated
and that statistical power was comparable to or better than known tests (e.g., t-tests). Indeed,
the ART-C procedure does not inflate Type I error rates and has similar or better power than parametric
alternatives. For more detail on ART-C, see
our UIST 2021 paper or
our [R] vignette.
Assuming the same nomenclature as above for Ai, Bj, and Ck, the following
steps conduct the ART-C procedure. See Elkin et al. (2021) for more formal mathematical notation.
Step 1: Factor Concatenation. Concatenate all factors whose levels are involved in the desired
post hoc pairwise comparisons. The result is a new "concatenated factor." For example, if we have
three factors A, B, and C, as above, and wish to compare levels of Ai (i=1...a) and
Bj (j=1...b), we would create a new factor AB whose levels are the concatenation of
A's and B's levels. That is, for any response Y for which A has level i and B has level j,
new factor AB has level ij. For example, if factor A has levels {1, 2} and factor B has levels {1, 2},
then concatenated factor AB would have levels {11, 12, 21, 22}.
After concatenation, the factors involved in the concatenation are dropped, and any factors not involved
in the concatentation are kept as-is. In our example, factors A and B are dropped and factor C is left unchanged.
So, our resulting two factors are AB and C.
Step 2: Alignment. As we did for main effects and interactions above, align all responses Y. In our example,
we would align Y for AB, for C, and for AB×C. However, since we are only interested in post hoc
pairwise comparisons among the levels of AB, we can drop the alignment columns for C and for AB×C.
Thus, we end up with one alignment column, Yaligned for AB.
Step 3: Ranking. As we did for main effects and interactions, assign midranks to all aligned responses
(Yaligned for ...). In our example, this means we create ranked column Yart-c for AB.
Step 4: Full Factorial ANOVA. Conduct a full-factorial ANOVA on the ranked response
(Yart-c for ...). The results of this omnibus test are ignored, but conducting it establishes
the statistical model within which the post hoc pairwise comparisons take place. In our example,
we would conduct an ANOVA with Yart-c for AB as the response, and AB, C, and AB×C
as the model factors.
Step 5: Pairwise Comparisons. Within the context of the full factorial ANOVA just conducted, we now
carry out post hoc pairwise comparisons. In our example, we could compare levels of ABij
for all ij. For example, as stated above, if factor A has levels {1, 2} and factor B has levels {1, 2},
then concatenated factor AB would have levels {11, 12, 21, 22}. To compare, say, {1, 2} vs. {2, 1}, one
would contrast AB's levels {12} vs. {21}. As usual, if multiple pairwise comparisons are
conducted, a correction for multiple comparisons should be used (e.g., Tukey, Holm, Bonferroni, etc.).
Sample Data
Four example data sets are included in the ARTool\data folder. The first two are from
Higgins et al. (1990). The first of these, named Higgins1990-Table1.csv, shows a mock data
set with two between-subjects factors named Row and Column. Each factor has
3 levels. Although in Higgins et al. (1990) this table is represented in wide-format,
ARTool requires long-format tables, so it has been rebuilt as such.
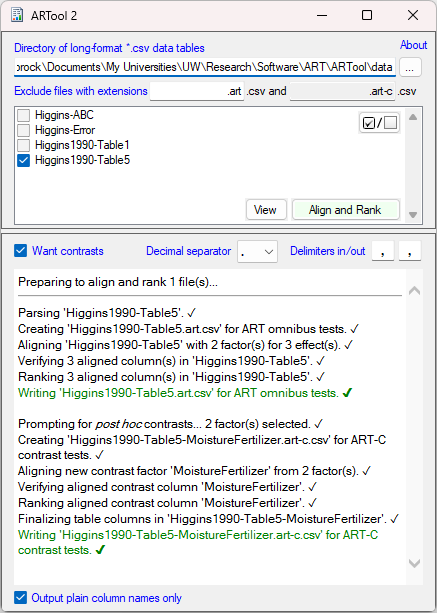
A second example is in Higgins1990-Table5.csv. This data is from a real study of moisture
levels and fertilizer as it affects the dry matter created in peat. It has two factors,
Moisture and Fertilizer. Moisture is a between-subjects factor of 3 levels,
while Fertilizer is a within-subjects factor of 4 levels. Twelve trays, each containing four
pots of peat, were put in a different moisture condition. Each peat pot on a tray was
subjected to a seperate fertilizer. Tray is therefore the experimental
unit, and each peat pot on each tray is a "trial." The response variable is
the amount of dry matter produced in a pot. In agricultural terminology, this is a classic split-plot
design, with Moisture as the whole-plot factor and Fertilizer as the subplot factor.
It is instructive to compare the layout of Table 5 in Higgins et al. (1990) to the long-format
layout in Higgins1990-Table5.csv.
Note that Higgins1990-Table5.csv has been run through Windows ARTool and so there also exists the
resulting Higgins1990-Table5.art.csv file. A post hoc contrasts table was also produced as
part of this process, resulting in Higgins1990-Table5-MoistureFertilizer.art-c.csv. A demonstration of
R's art() and art.con() functions and their comparison to manually processing
these *.csv files is given in the R code file Higgins.R.
A third example is Higgins-ABC.csv, which is a mock data set with two between-subjects factors,
A and B, and a third within-subjects factor, C. A parametric analysis
of variance will show that all main effects and the A×B interaction are significant. An
analysis of variance on ART data will show that the same significance conclusions are drawn.
A fourth example is Higgins-ABC.csv renamed to Higgins-Error.csv and given an invalid
non-numeric response ("nnn") on the third row of data. When analyzed by ARTool, a red-text error is
produced. ARTool produces descriptive error messages, identifying where errors occur so they can be inspected
and possibly remedied.
References & Further Reading
Aitchison, J. and Brown, J.A.C. (1957). The Lognormal Distribution. Cambridge, England: Cambridge University Press. DOI
Akritas, M.G. and Brunner, E. (1997). A unified approach to rank tests for mixed models. Journal of Statistical Planning and Inference 61 (2), pp. 249-277. DOI
Akritas, M.G. and Osgood, D.W. (2002). Guest editors' introduction to the special issue on nonparametric models. Sociological Methods and Research 30 (3), pp. 303-308. DOI
Barefield, E. and Mansouri, H. (2001). An empirical study of nonparametric multiple comparison procedures in randomized blocks 13 (4), pp. 591-604. DOI
Beasley, T.M. (2002). Multivariate aligned rank test for interactions in multiple group repeated measures designs. Multivariate Behavioral Research 37 (2), pp. 197-226. DOI
Berry, D.A. (1987). Logarithmic transformations in ANOVA. Biometrics 43 (2), pp. 439-456. DOI
Boik, R.J. (1979). Interactions, partial interactions, and interaction contrasts in the analysis of variance. Psychological Bulletin 86 (5), pp. 1084-1089. DOI
Conover, W.J. and Iman, R.L. (1981). Rank transformations as a bridge between parametric and nonparametric statistics The American Statistician 35 (3), pp. 124-129. DOI
Elkin, L.A., Kay, M., Higgins, J. and Wobbrock, J.O. (2021). An aligned rank transform procedure for multifactor contrast tests. Proceedings of the ACM Symposium on User Interface Software and Technology (UIST '21). Virtual Event (October 10-14, 2021). New York: ACM Press, pp. 754-768. DOI
Fawcett, R.F. and Salter, K.C. (1984). A Monte Carlo study of the F test and three tests based on ranks of treatment effects in randomized block designs. Communications in Statistics: Simulation and Computation 13 (2), pp. 213-225. DOI
Frederick, B.N. (1999). Fixed-, random-, and mixed-effects ANOVA models: A user-friendly guide for increasing the generalizability of ANOVA results. In Advances in Social Science Methodology, B. Thompson (ed). Stamford, Connecticut: JAI Press, pp. 111-122. Link
Friedman, M. (1937). The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association 32 (200), pp. 675-701. DOI
Higgins, J.J., Blair, R.C. and Tashtoush, S. (1990). The aligned rank transform procedure. Proceedings of the Conference on Applied Statistics in Agriculture. Manhattan, Kansas: New Prairie Press, pp. 185-195. DOI
Higgins, J.J. and Tashtoush, S. (1994). An aligned rank transform test for interaction. Nonlinear World 1 (2), pp. 201-211.
Higgins, J.J. (2004). Introduction to Modern Nonparametric Statistics. Pacific Grove, California: Duxbury Press. Amazon
Hodges, J.L. and Lehmann, E.L. (1962). Rank methods for combination of independent experiments in the analysis of variance. Annals of Mathematical Statistics 33 (2), pp. 482-497.Link
Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics 6 (2), pp. 65-70. Link
Kaptein, M., Nass, C. and Markopoulos, P. (2010). Powerful and consistent analysis of Likert-type rating scales. Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI '10). New York: ACM Press, pp. 2391-2394. DOI
Kay, M. (2021). Effect sizes with ART. ARTool [R] package vignette. Updated October 12, 2021. Link
Kay, M., Elkin, L.A. and Wobbrock, J.O. (2021). Contrast tests with ART. ARTool [R] package vignette. Updated October 12, 2021. Link
Kruskal, W.H. and Wallis, W.A. (1952). Use of ranks in one-criterion variance analysis. Journal of the American Statistical Association 47 (260), pp. 583-621. DOI
Lehmann, E.L. (2006). Nonparametrics: Statistical Methods Based on Ranks. New York: Springer. Springer
Littell, R.C., Henry, P.R. and Ammerman, C.B. (1998). Statistical analysis of repeated measures data using SAS procedures. Journal of Animal Science 76 (4), pp. 1216-1231.DOI
Mann, H.B. and Whitney, D.R. (1947). On a test of whether one of two random variables is stochastically larger than the other. Annals of Mathematical Statistics 18 (1), pp. 50-60.Link
Mansouri, H. (1999). Aligned rank transform tests in linear models. Journal of Statistical Planning and Inference 79 (1), pp. 141-155.DOI
Mansouri, H. (1999). Multifactor analysis of variance based on the aligned rank transform technique. Computational Statistics and Data Analysis 29 (2), pp. 177-189. DOI
Mansouri, H., Paige, R.L. and Surles, J.G. (2004). Aligned rank transform techniques for analysis of variance and multiple comparisons. Communications in Statistics: Theory and Methods 33 (9), pp. 2217-2232. DOI
Mansouri, H. (2015). Simultaneous inference based on rank statistics in linear models. Journal of Statistical Computation and Simulation 85 (4), pp. 660-674. DOI
Marascuilo, L.A. and Levin, J.R. (1970). Appropriate post hoc comparisons for interaction and nested hypotheses in analysis of variance designs: The elimination of Type IV errors. American Educational Research Journal 7 (3), pp. 397-421. DOI
Richter, S.J. (1999). Nearly exact tests in factorial experiments using the aligned rank transform. Journal of Applied Statistics 26 (2), pp. 203-217. DOI
Salter, K.C. and Fawcett, R.F. (1985). A robust and powerful rank test of treatment effects in balanced incomplete block designs. Communications in Statistics: Simulation and Computation 14 (4), pp. 807-828. DOI
Salter, K.C. and Fawcett, R.F. (1993). The ART test of interaction: A robust and powerful rank test of interaction in factorial models. Communications in Statistics: Simulation and Computation 22 (1), pp. 137-153. DOI
Sawilowsky, S.S. (1990). Nonparametric tests of interaction in experimental design. Review of Educational Research 60 (1), 91-126. DOI
Schuster, C. and von Eye, A. (2001). The relationship of ANOVA models with random effects and repeated measurement designs. Journal of Adolescent Research 16 (2), pp. 205-220.DOI
Tukey, J.W. (1949). Comparing individual means in the analysis of variance. Biometrics 5 (2), pp. 99-114. DOI
Wilcoxon, F. (1945). Individual comparisons by ranking methods. Biometrics Bulletin 1 (6), pp. 80-83.DOI
Wobbrock, J.O., Findlater, L., Gergle, D. and Higgins, J.J. (2011). The aligned rank transform for nonparametric factorial analyses using only ANOVA procedures. Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI '11). New York: ACM Press, pp. 143-146.DOI
Acknowledgements
This work was supported in part by the National Science Foundation under grants IIS-0811884 and IIS-0811063.
Any opinions, findings, conclusions or recommendations expressed in this work are those of the authors and
do not necessarily reflect those of the National Science Foundation.