 HDS Lab Director Cecilia Aragon recently received a Fulbright award from the U.S. Department of State. The purpose of the Core Fulbright U.S. Scholar Program is to enhance the exchange of knowledge and skills between people of the United States and other countries. Dr. Aragon will use the award to support work at the Universidad Técnica Federico Santa María in Valparaiso, Chile. There, she will collaborate with Chilean scholars to conduct research on human-centered data science and social media analysis, and will teach a course in visual analytics.
HDS Lab Director Cecilia Aragon recently received a Fulbright award from the U.S. Department of State. The purpose of the Core Fulbright U.S. Scholar Program is to enhance the exchange of knowledge and skills between people of the United States and other countries. Dr. Aragon will use the award to support work at the Universidad Técnica Federico Santa María in Valparaiso, Chile. There, she will collaborate with Chilean scholars to conduct research on human-centered data science and social media analysis, and will teach a course in visual analytics.
Posted by Cecilia Aragon
on January 20, 2017
Posted by Cecilia Aragon
on January 20, 2017

Nan-Chen Chen and Dr. Been Kim of the Allen Institute for Artificial Intelligence.
HDS Lab member Nan-Chen Chen was recently named the 2016 Intern of the Year at the Allen Institute for Artificial Intelligence, where she worked with Dr. Been Kim on the Aristo project. In that role, Chen designed and built a visual analytics tool called QSAnglyzer that is now being used by developers at the Allen Institute working on a question answering system.
Posted by Cecilia Aragon
on October 14, 2016

The Open Sidewalks Team: Nick Bolten, Kaicheng Tan, Jess Hamilton, Meg Drouhard, Tom Disley, Anat Caspi, Vaughn Iverson, and Bryna Hazelton
Lab member Meg Drouhard worked as a fellow for the Data Science for Social Good program at UW’s eScience Institute over the summer. Meg’s “Open Sidewalks” team–four fellows, two data scientists, and two project leads–worked to improve standards and make more pedestrian data openly available. In particular, they focused on expanding access to data that could help people with limited mobility better navigate cities. The project was featured on the White House Fact Sheet (https://tcat.cs.washington.
Posted by Cecilia Aragon
on June 07, 2016
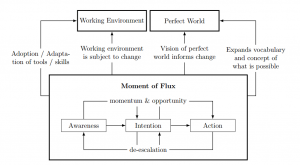
The Cycle of Deliberate Change developed in Katie Kuksenok’s dissertation.
HDS Lab member Katerena Kuksenok successfully defended her doctoral dissertation on the interaction between programming and scientific practices in oceanography. As projects involve more people, longer time spans, and more ambitious collaboration between disciplines, understanding how coding practices influence scientific inquiry is increasingly important. The discussion of “best practices” in open science encourages the sharing of negative results and disappointing data as a top priority. This call for reflection on failure must be extended to include code work. With data as well as with code sharing, repeated “best practices” are not sufficient to inspire change, even for those scientists who openly feel they “should” do it. The conceptual framework Katie proposes creates optimistic vocabulary for reflecting upon deliberate change.
Also, HDS Lab member and communication graduate student, Anissa Tanweer, completed her general exams this quarter and advanced to PhD candidacy. Her dissertation work will focus on the drive to use big data in the pursuit of social change and policy formation, and the cross-sector collaborations that support that movement.
