I.4: Multiple Binding: Random-ordered Models
Continuing from our discussion of sequential binding models, we move to a slightly more rigorous description of multiple binding: random-ordered models. In a two-distinct-site random-ordered model, there are two substrate binding sites on the enzyme, each with their own KDs. Once either site is occupied, the substrate can bind to the other site with an altered KD. If the substrate binding at one site enhances the affinity of binding at another site, then the enzyme exhibits positive cooperativity. If the reverse is true (binding at one site decreases the affinity of the other site), the enzyme shows negative cooperativity.
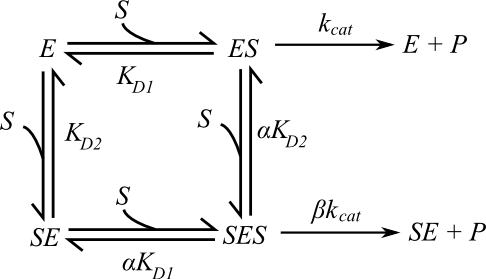
In the scheme above, ES and SE are the two singly-occupied complexes and SES is the doubly-occupied complex. ES and SES are both productive: the parameter β reflects how productive the SES complex is relative to ES, in that values below 1 imply substrate inhibition and values above 1 imply activation. The cooperativity parameter α shows how binding at one site affects the affinity at the other: values below 1 indicate increased affinity (positive cooperativity) and values above 1 indicate negative cooperativity.
Extending the quick derivation at the end of the previous section on sequential binding, the specific terms for ES, SE and SES are [S]/KD1, [S]/KD2, and [S]2/αKD1KD2 respectively. Therefore, the velocity equation for the system is:

If one binding site is much higher-affinity than the other, the specific term associated with the weaker-binding (higher KD) site is negligible and can therefore be omitted from this equation, which then resembles the velocity equation previously derived for the two-site sequential model. In other words, sequential binding models are a special case of random-ordered models where one binding site is much higher-affinity than the other (KD1 >> KD2 or KD1 << KD2).
Although sequential models are less general than random-ordered models, they have fewer free parameters and so are easier to use when fitting experimental data. This means that, in cases where they are applicable, sequential models are often a better choice than random-ordered models when it comes to analyzing experimental data.