Originally posted on June 23, 2019 at https://fanfictiondatascience.tumblr.com/post/185799336200/do-substantive-reviews-improve-authors-writing.
Introduction
The goal of this research is to find further evidence for the benefits of distributed mentoring. Distributed mentoring is “a kind of mentoring that is uniquely suited to networked communities, where people of all ages and experience levels engage with and support one another through a complex, interwoven tapestry of interactive, cumulatively sophisticated advice and informal instruction” [1]. This involves multiple kinds of feedback exchanged between many mentors and mentees. In this research project, we used machine learning to classify Fanfiction.net reviews by their category within distributed mentoring theory.
Earlier research in our group published in the paper ‘More Than Peer Production: Fanfiction Communities as Sites of Distributed Mentoring’ has outlined 13 categories that were observed in Fanfiction.net reviews [2]. We used shallow positive, targeted positive, targeted constructive, and targeted positive & constructive for this analysis, as they are the four mutually exclusive codes. Table 1 below provides a formal description and percentage of reviews for each of the categories [2].
Table 1: Description and Percentage of Categories (based on 4500 reviews)

(Note: percentages add up to more than 100% because a review could be in multiple categories).
An
example of a shallow positive review is “Great story!”, targeted
positive is “I loved the character development of James”, and a targeted
constructive review is “You could have described the battle scene
better!” Targeted positive & constructive reviews contains both
targeted positive and targeted constructive comments.
Our overarching research question is “Do certain review categories correlate with various attributes of distributed mentoring?” For example, we want to explore whether substantive, targeted reviews improve authors’ writing. This research would be beneficial to the fanfiction community, as it would provide an outline to members of the community on how to effectively impact and interact with authors. The theory of distributed mentoring is an applicable framework to use, as it discusses the effect of networked communities. To apply this theory, we used the public reviews available in the fanfiction community. Since there are numerous types of reviews, we used the codes listed in Table 1 to classify the reviews.
To classify all Fanfiction.net reviews, roughly 177 million, we explored machine learning classification, as manual coding would be impossible. Classification is a process of predicting the review category for a given set of reviews.
Our goal for this blog was to find the best machine learning model for review classification. We could then use this model to expand our results to the entire Fanfiction.net reviews dataset. Our baseline classification tool was ALOE (Affect Labeler of Expressions), an open source tool developed to train and test machine learning classifiers to automatically label chat messages with different emotion or affect categories [3]. In addition, we attempted various algorithms such as logistic regression, support vector machines, and Naive Bayes. This blog post discusses our approach to running ALOE as well as creating each of the aforementioned machine learning models.
Dataset
To conduct machine classification, we required data to train the model to learn how reviews relate to a certain category. We leveraged a dataset manually classified by previous participants in the UW Human-Centered Data Science Lab research group. Our dataset contained ~8000 manually classified reviews.
Method
The measures of success for performance were accuracy, precision, and recall. Accuracy is the number of correct predictions. This measure, however, can be misleading in classification problems. In the field of data science, we call a positive value true and a negative value false. In this case the value is positive if the review corresponds to the category in question and false otherwise. For example, if a dataset has 99 positive data points and 1 negative data points, a model that predicts only positive would receive a 0.99 accuracy. Therefore, we also used precision and recall to provide a holistic perspective. Precision is ‘how many negative data points did I include in my list of positively predicted examples’, and recall is ‘how many positive data points did I miss’. An average range for precision and recall is 0.6 – 0.7. Anything below 0.6 may signify that the results are not valid while and anything above 0.7 is generally considered a really good score that validates our accuracy.
Figure 1: Image from Wikipedia visually describing Precision and Recall

1. ALOE
We were able to run ALOE by following the documentation at https://github.com/etcgroup/aloe.
2. Other Classifiers
2.1 Logistic Regression
Logistic Regression is a method commonly used when the inputs of the model are categories. We experimented with multiple different parameters and sought a set of parameters that yield the best result from the model.
2.2 Naive Bayes
Naive Bayes is a family of machine learning based on applying Bayes’ theorem to calculate certain probabilities. We explored 3 types of Naive Bayes classifiers on the four categories of data. These were the Gaussian, Bernoulli and Multinomial Naive Bayes methods.
2.3 Support Vector Machine (SVM)
SVM is a method to find the best division between two classes. We explored three different SVM models: default, linear, and optimal. We used a technique to find the best parameters for each of these models.
When using the four categories defined above, we received low precision and recall scores for targeted constructive and targeted positive & constructive. Hence we decided to combine the three targeted categories in order to solidify our results. This is because there are very few reviews in the dataset for the latter two categories, and all targeted categories qualify as “substantive” since they provide specific feedback to authors. Consequently, we decided to add the update encouragement category, as 27.6% of our dataset is classified as this code. Update encouragement is a category that represents all reviews that encourage the author to write more [2]. These changes enable a more accurate comparison between the various models.
Results
After these changes, we got the following results for our models on shallow positive, targeted, and update encouragement. All values are representative of percentages, from a scale from 0 to 1.
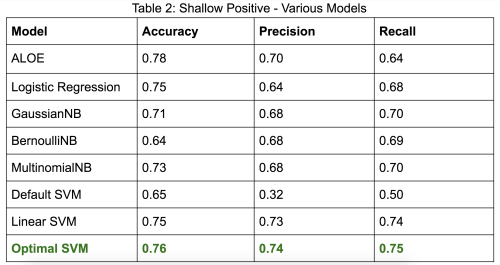

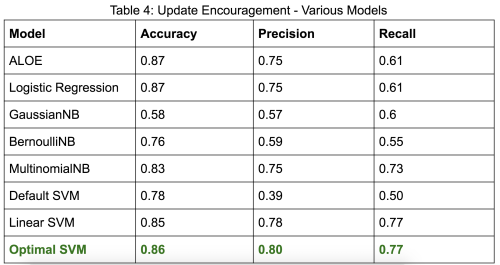
Conclusion
We will expand these results by classifying the entire Fanfiction.net dataset, 177 million reviews, by using Optimal SVM to predict shallow positive and update encouragement reviews and ALOE to predict targeted reviews. After which, we plan to proceed with our analysis between these review categories and attributes of distributed mentoring such as improvement of writing and participation rate. As a starting point, we will explore whether targeted reviews impact authors’ lexical diversity – which is an indicator of improvement in the authors’ writing and a learning gain from online informal learning. Additionally, we will brainstorm other metrics to measure learning and distributed mentoring. Overall, we are delighted that our changes gave positive results and were able to create models that performed better than our baseline, ALOE. A better model means we can more accurately classify reviews and expand our results to provide a blueprint to the fanfiction community on how to effectively impact and interact with authors.
Citations
- Aragon C. Human-Centered Data Science Lab » Distributed Mentoring in Fanfiction Communities Human-Centered Data Science Lab. Depts.washington.edu. https://depts.washington.edu/hdsl/research/distributed-mentoring/. Published 2019. Accessed June 5, 2019.
- Evans, S., Davis, K., Evans, A., Campbell, J. A., Randall, D. P., Yin, K., & Aragon, C. (2017, February). More than peer production: fanfiction communities as sites of distributed mentoring. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing(pp. 259-272). ACM.
- Brooks M. etcgroup/aloe. GitHub. https://github.com/etcgroup/aloe.
