2026

arXiv 2026
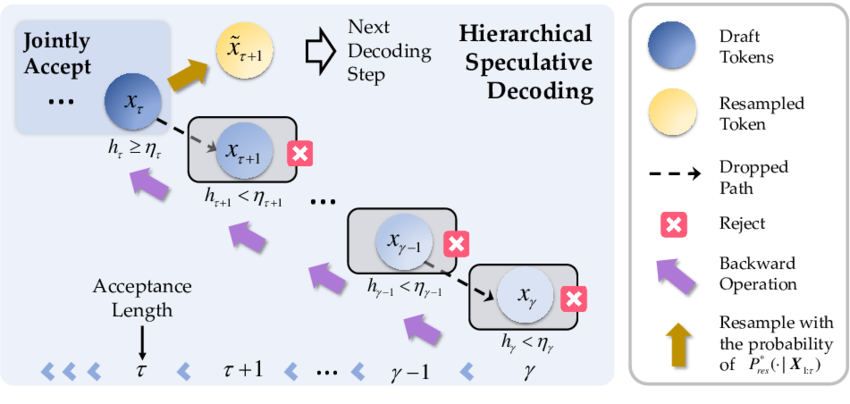
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
In International Conference on Learning Representations (ICLR), Oral presentation, 2026
ACL Findings 2026
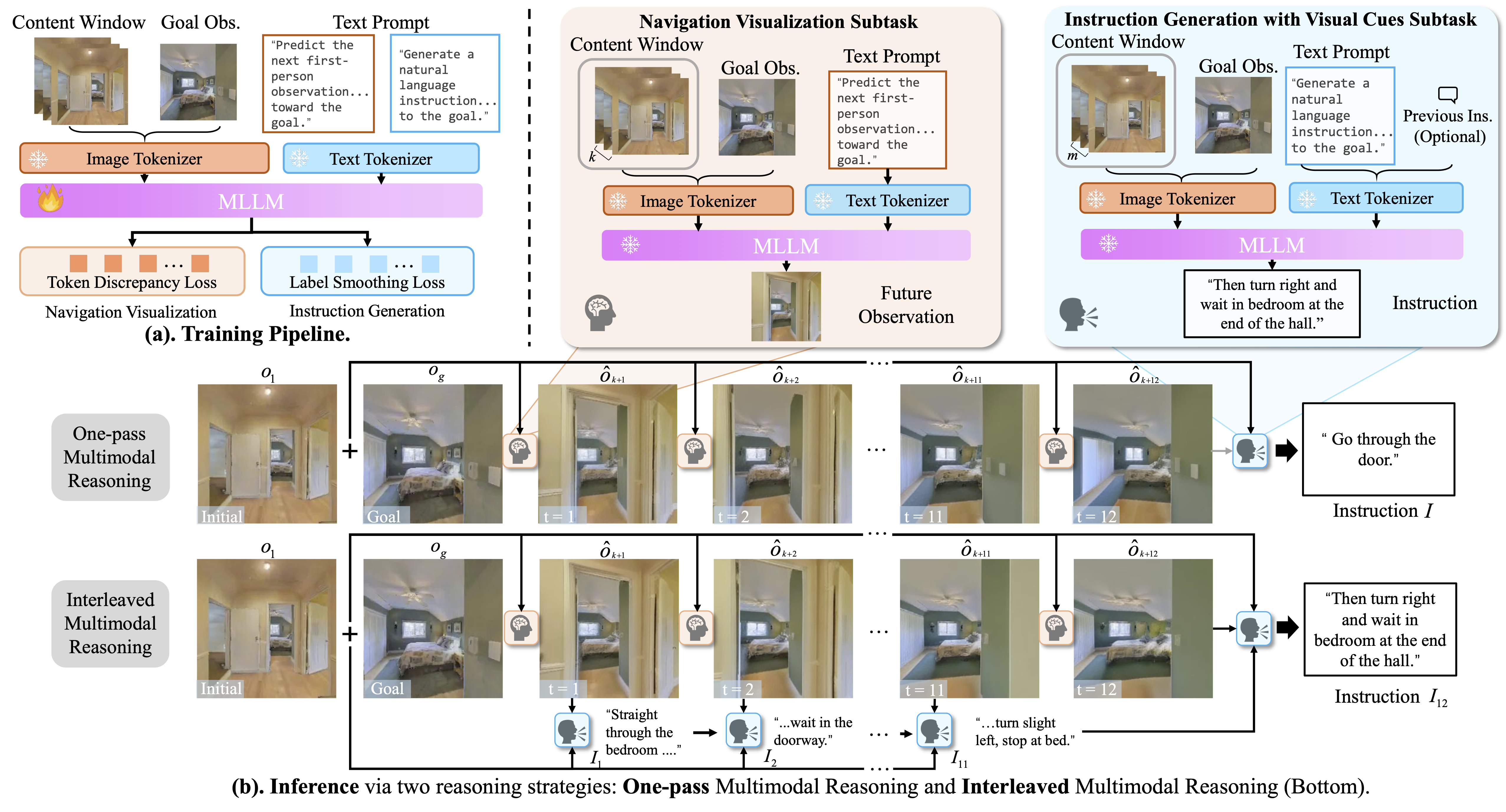
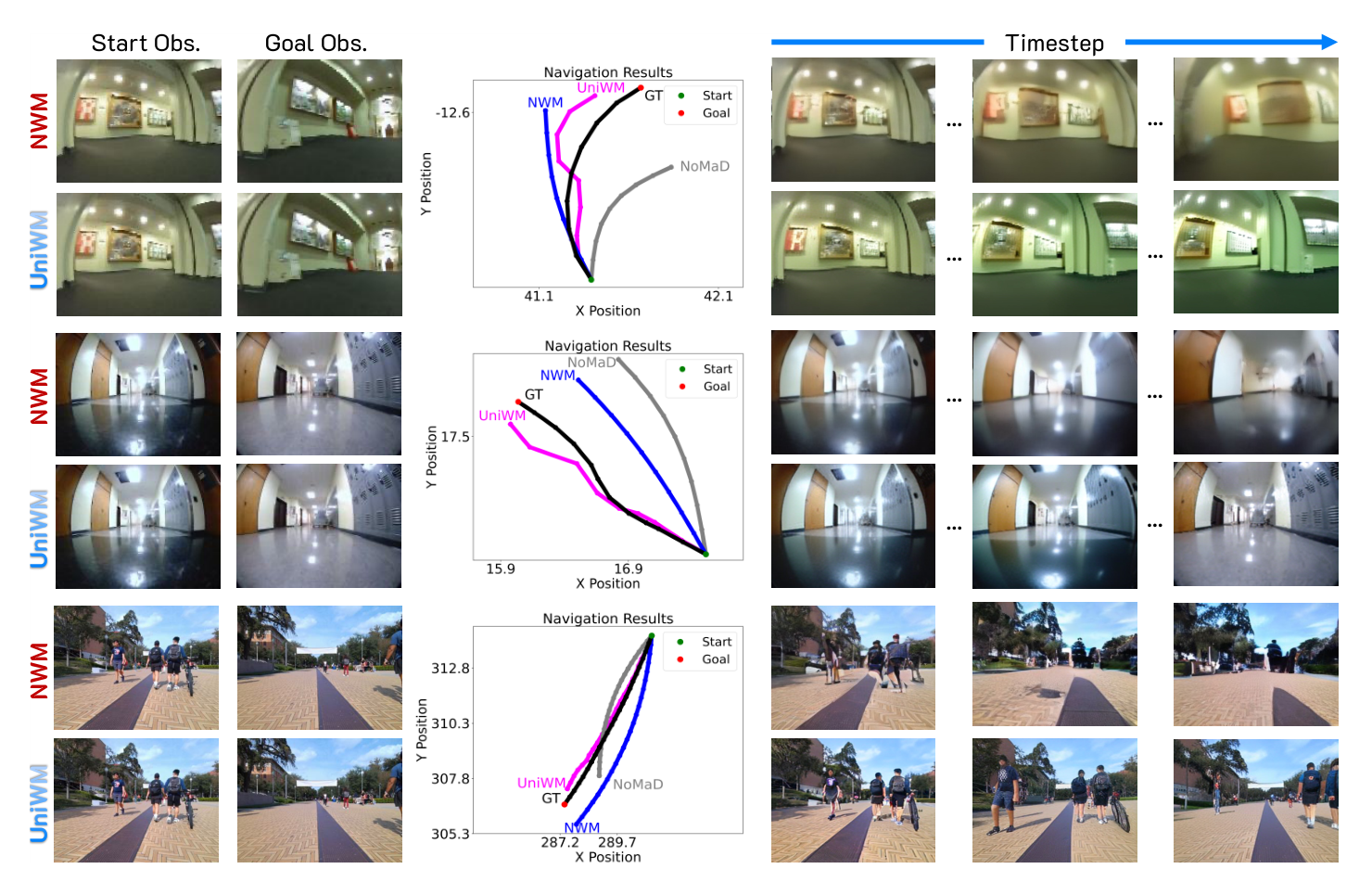
GoVIG: Goal-Conditioned Visual Navigation Instruction Generation via Multimodal Reasoning
Findings of the Association for Computational Linguistics (ACL Findings), 2026
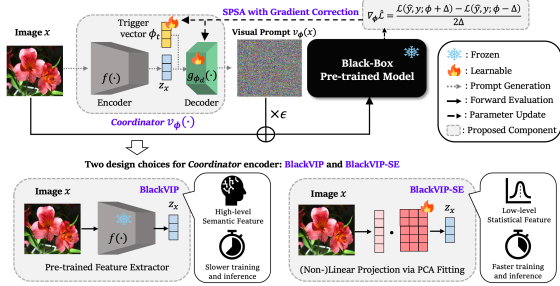
Robust Adaptation of Foundation Models with Black-Box Visual Prompting
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026
arXiv 2026
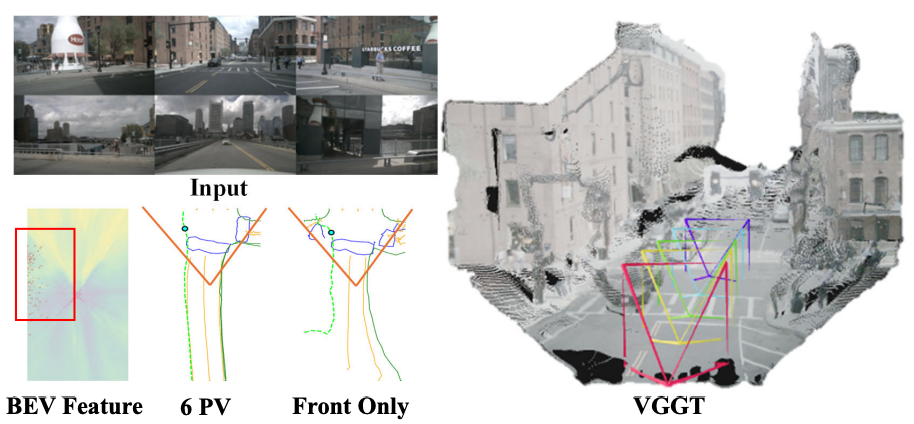
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
arXiv preprint, 2026
arXiv 2026
arXiv 2026
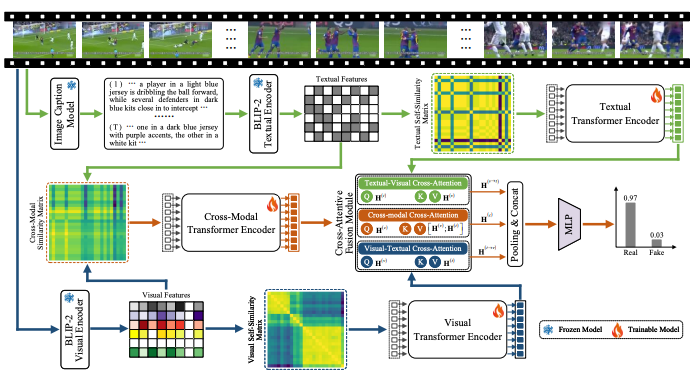
ATSS: Detecting AI-Generated Videos via Anomalous Temporal Self-Similarity
arXiv preprint, 2026
2025

MaxSup: Overcoming Representation Collapse in Label Smoothing
In Advances in Neural Information Processing Systems (NeurIPS), Oral presentation, 2025
StableAnimator: High-Quality Identity-Preserving Human Image Animation
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
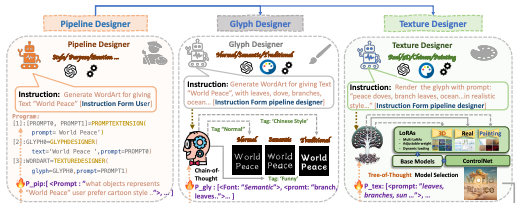
MetaDesigner: AI-Driven, User-Centric, Multilingual WordArt Synthesis
In International Conference on Learning Representations (ICLR), 2025

Emphasizing Discriminative Features for Dataset Distillation in Complex Scenarios
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
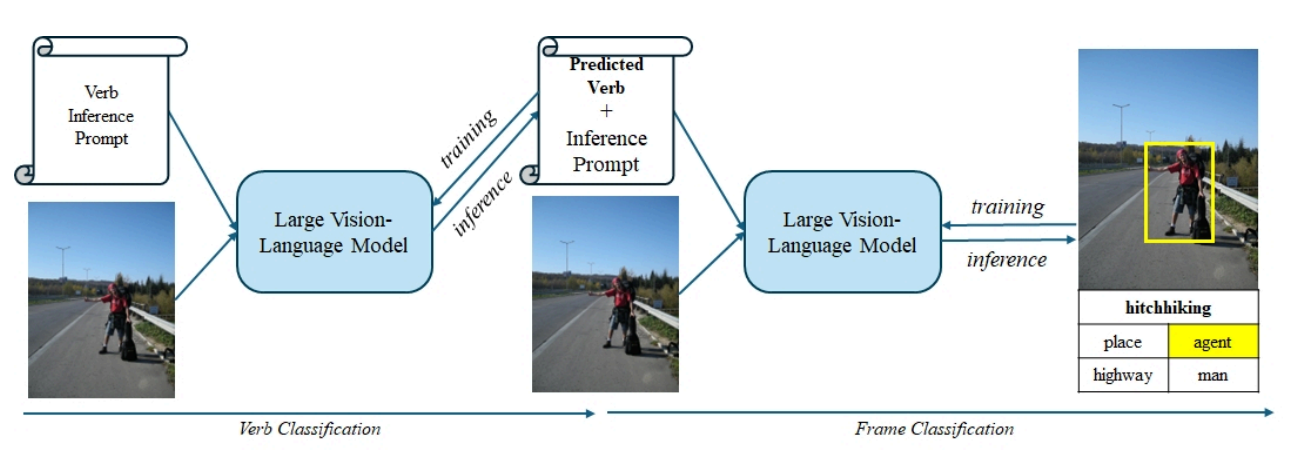
ICME 2025 · Oral
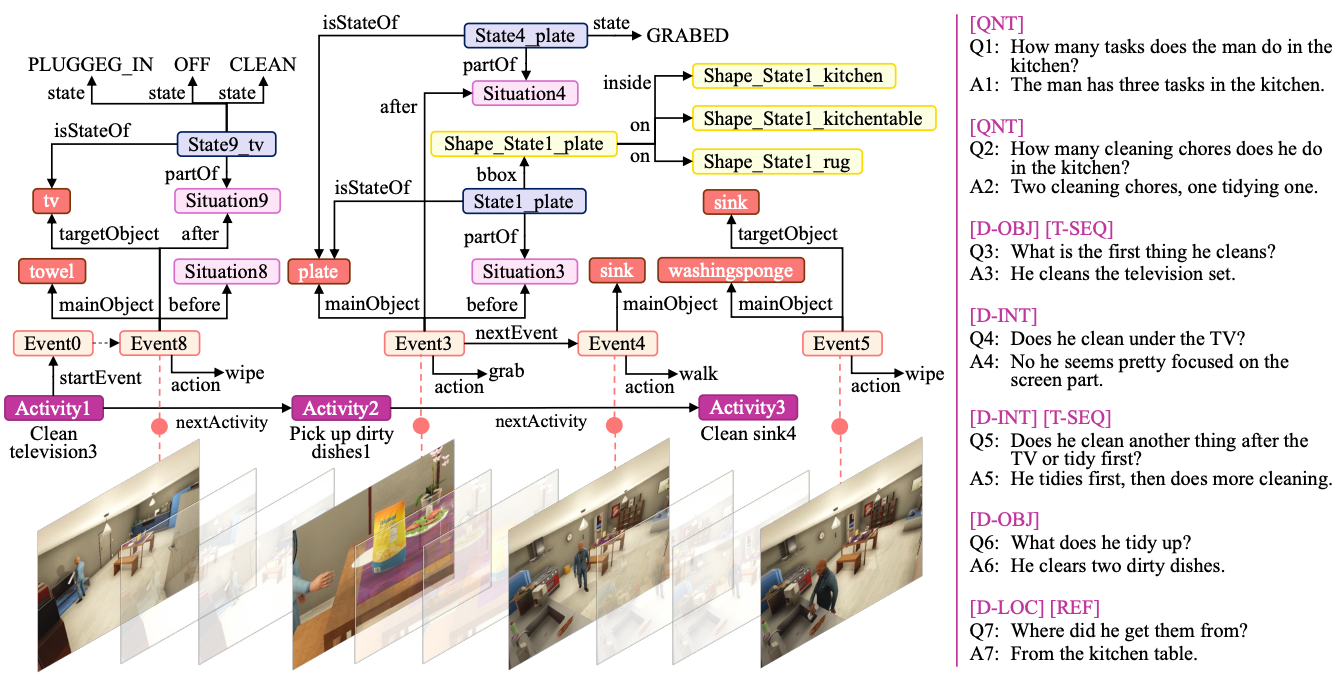
VDAct: A Video-grounded Dialogue Dataset and Metric for Event-driven Activities
In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Oral presentation, 2025
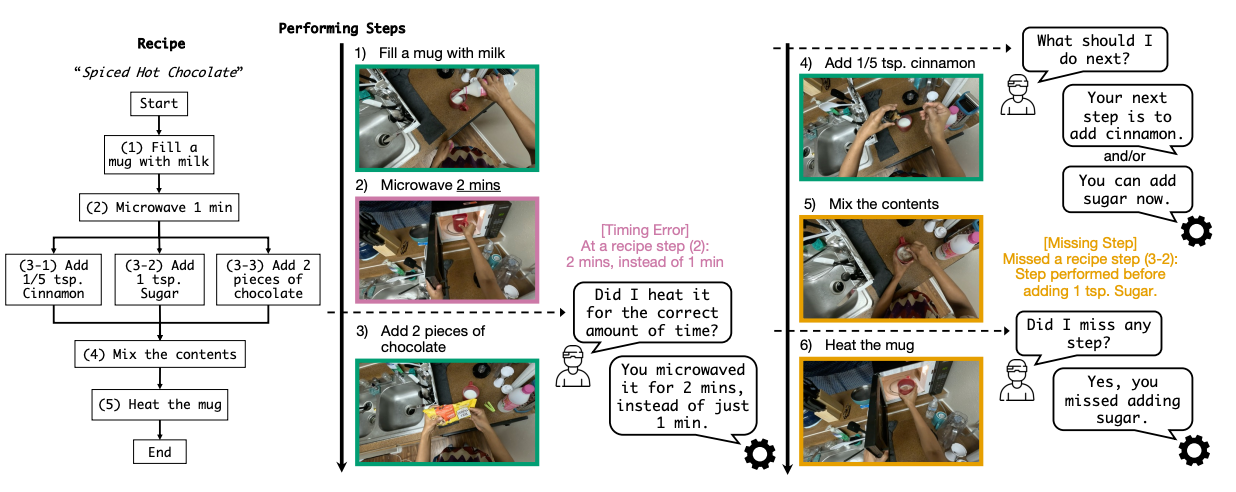
ProMQA: Question Answering Dataset for Multimodal Procedural Activity Understanding
In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Oral presentation, 2025
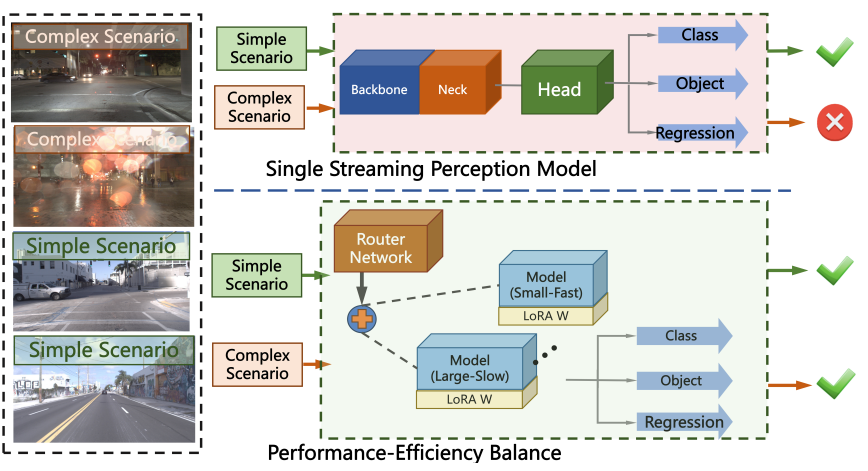
DyRoNet: Dynamic Routing and Low-Rank Adapters for Autonomous-Driving Streaming Perception
In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
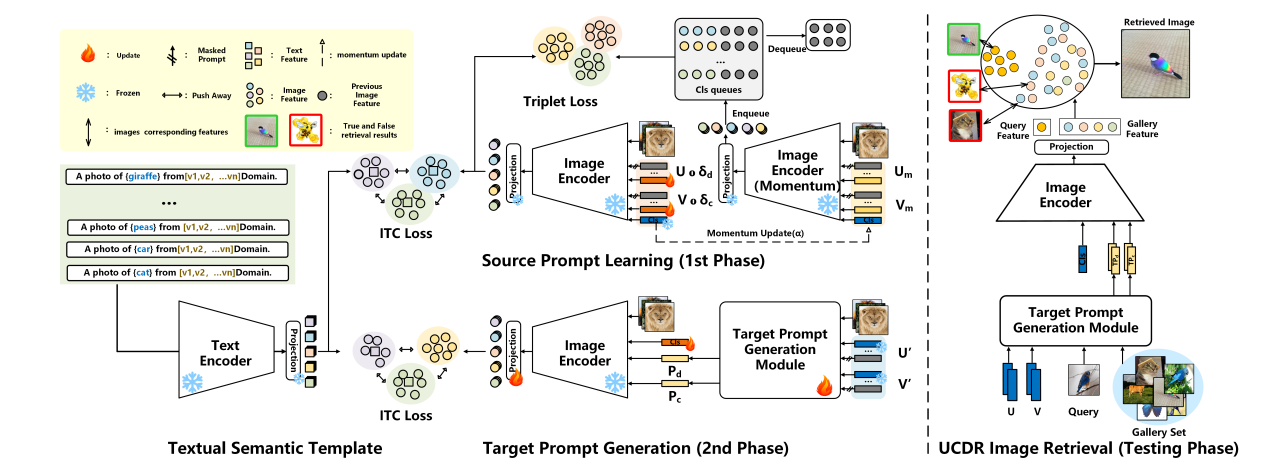
UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
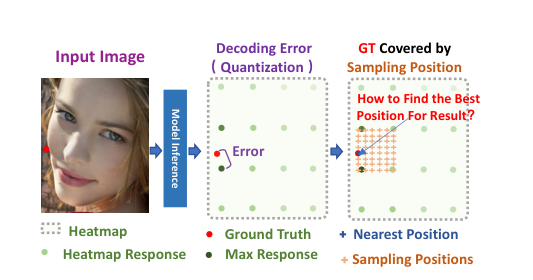
POPoS: Improving Efficient and Robust Facial Landmark Detection with Parallel Optimal Position Search
In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025

CVPR 2025 Workshop · Best Paper
Securing the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Anti-UAV Workshop, Workshop Best Paper Award, 2025
MotionFollower: Editing Video Motion via Score-Guided Diffusion
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
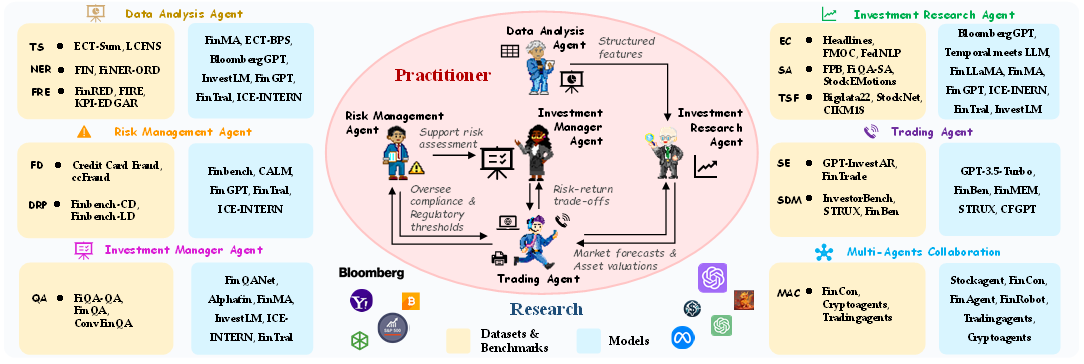
Large Language Model Agents in Finance: A Survey Bridging Research, Practice, and Real-World Deployment
Findings of the Association for Computational Linguistics: Empirical Methods in Natural Language Processing (EMNLP Findings), 2025
ICME 2025
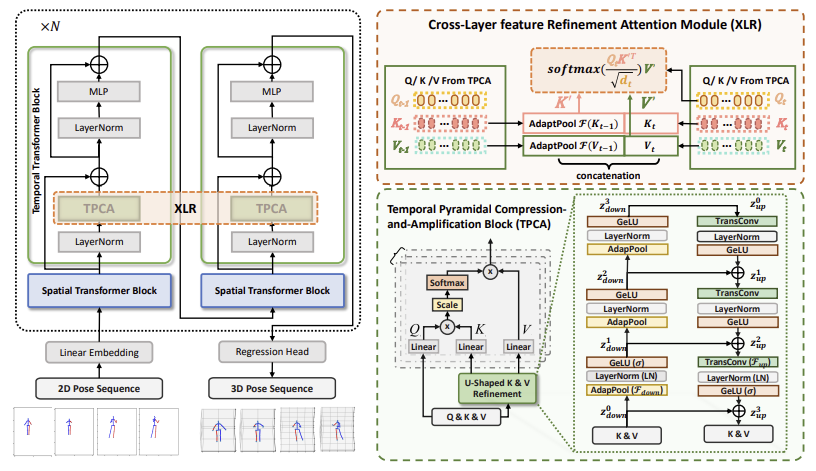
Refined Temporal Pyramidal Compression-and-Amplification Transformer for 3D Human Pose Estimation
In IEEE International Conference on Multimedia and Expo (ICME), 2025
ICASSP 2025
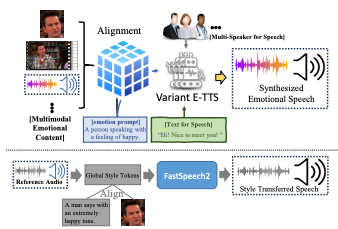
UMETTS: A Unified Framework for Emotional Text-to-Speech Synthesis with Multimodal Prompts
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
ICASSP 2025
DeformAvatar: Point-Based Human Avatar Re-targeting and Rendering
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
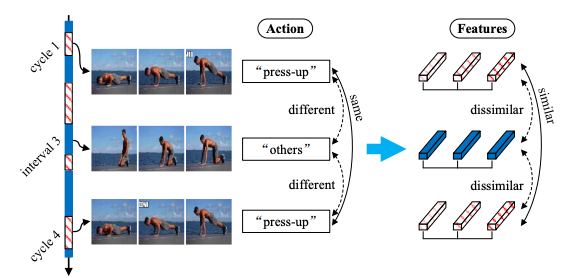
IVAC-P2L: Leveraging Irregular Repetition Priors for Improving Video Action Counting
IEEE Transactions on Multimedia (TMM), 2025

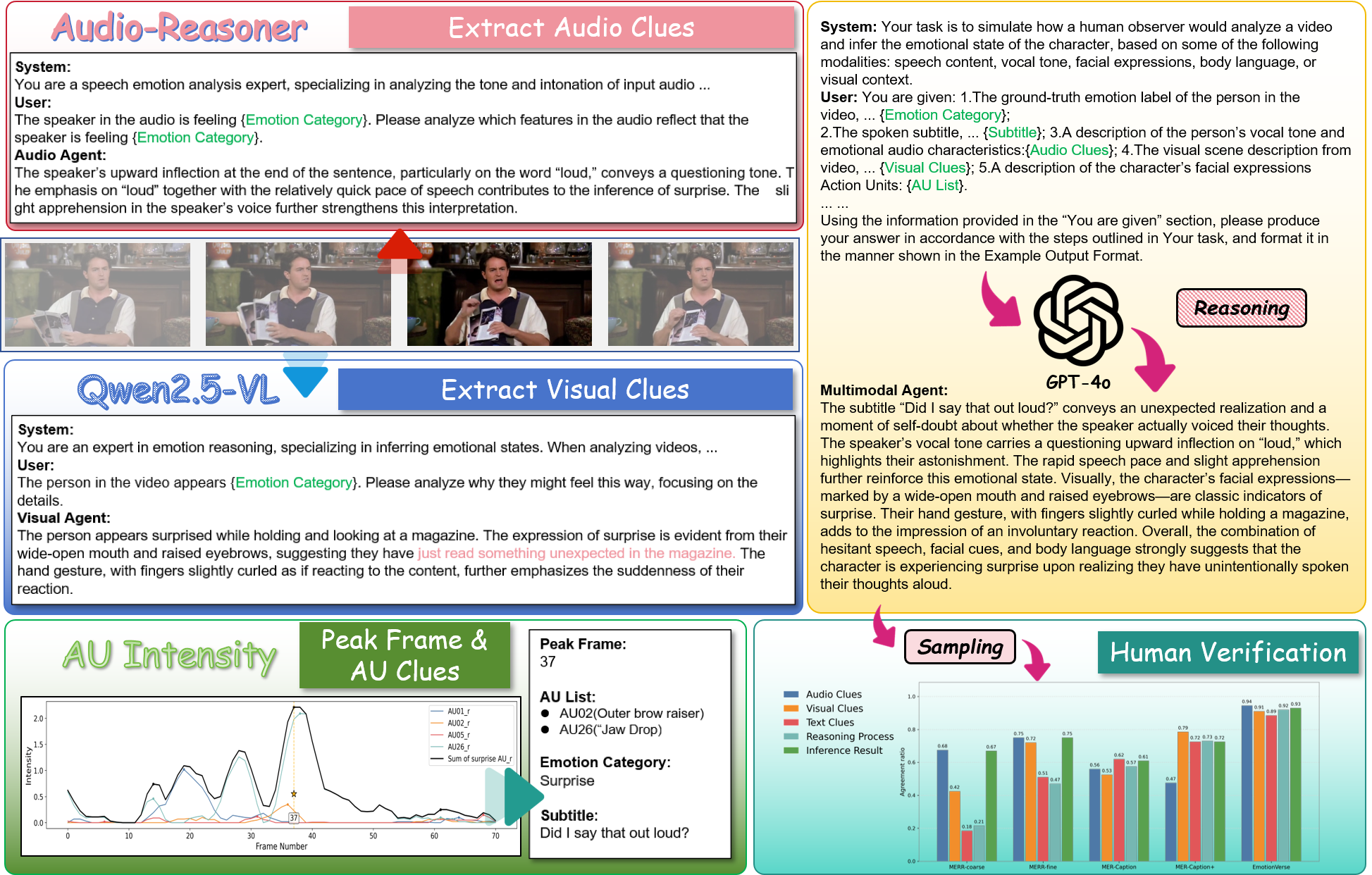
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) NEXD Workshop, Oral presentation, 2025

Neurocomputing 2025
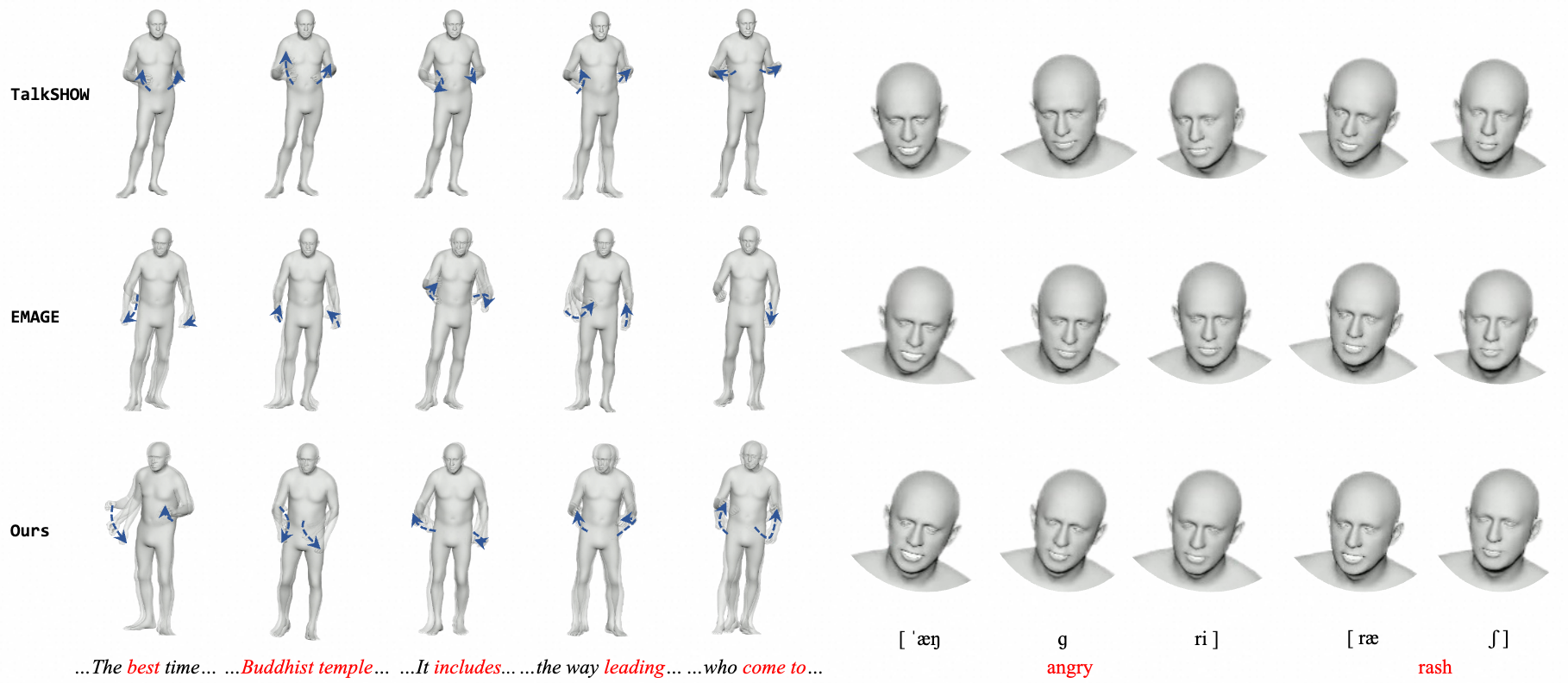
Combo: Co-Speech Holistic 3D Human Motion Generation and Efficient Customizable Adaptation in Harmony
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
CVIU 2025
LEAF: Unveiling Two Sides of the Same Coin in Semi-Supervised Facial Expression Recognition
Computer Vision and Image Understanding (CVIU), 2025

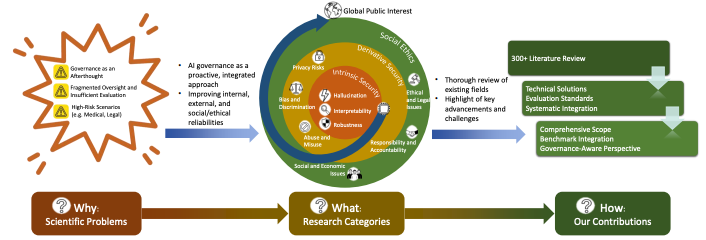
Never Compromise to Vulnerabilities: A Comprehensive Survey on AI Governance
arXiv preprint, 2025
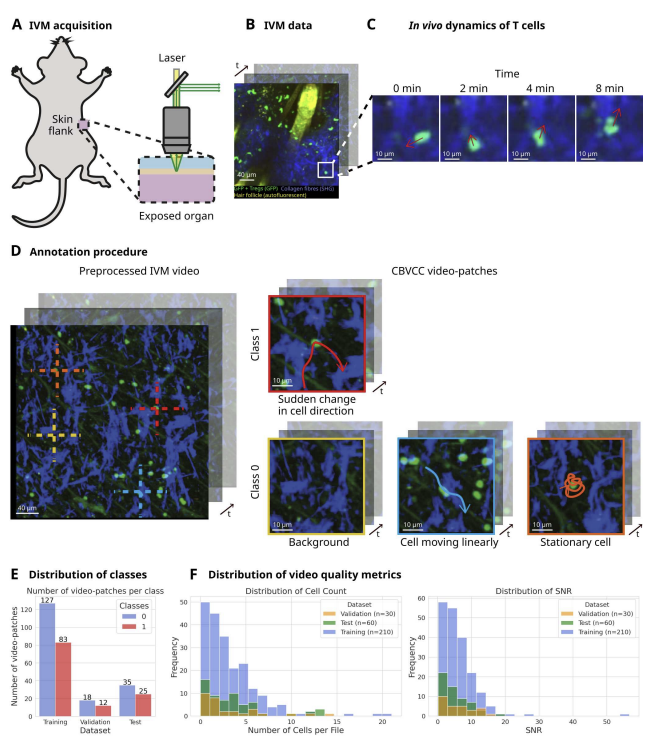
arXiv 2026
Cell Behavior Video Classification Challenge: A Benchmark for Computer Vision Methods in Live-Cell Imaging
CBVCC Challenge, under submission, 2025
2024
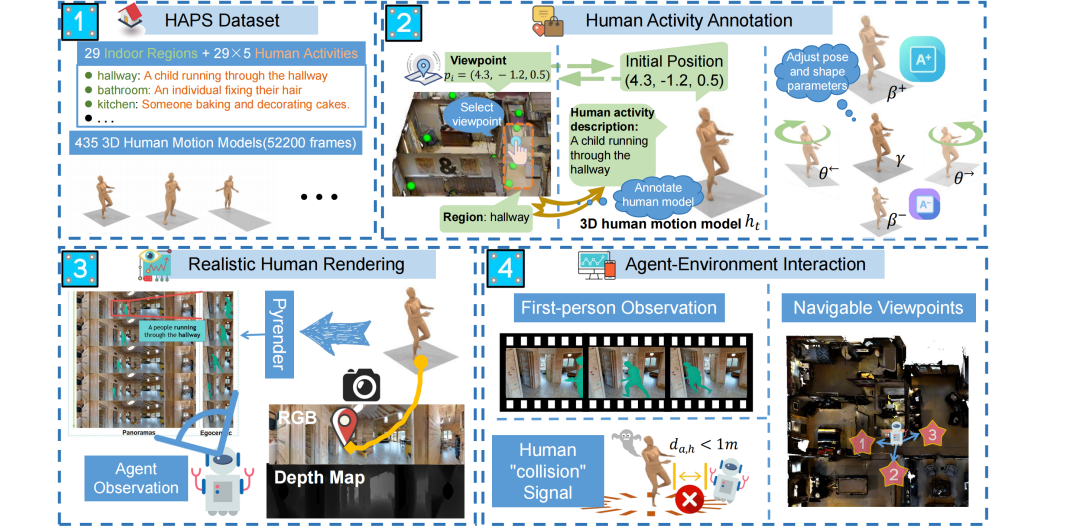
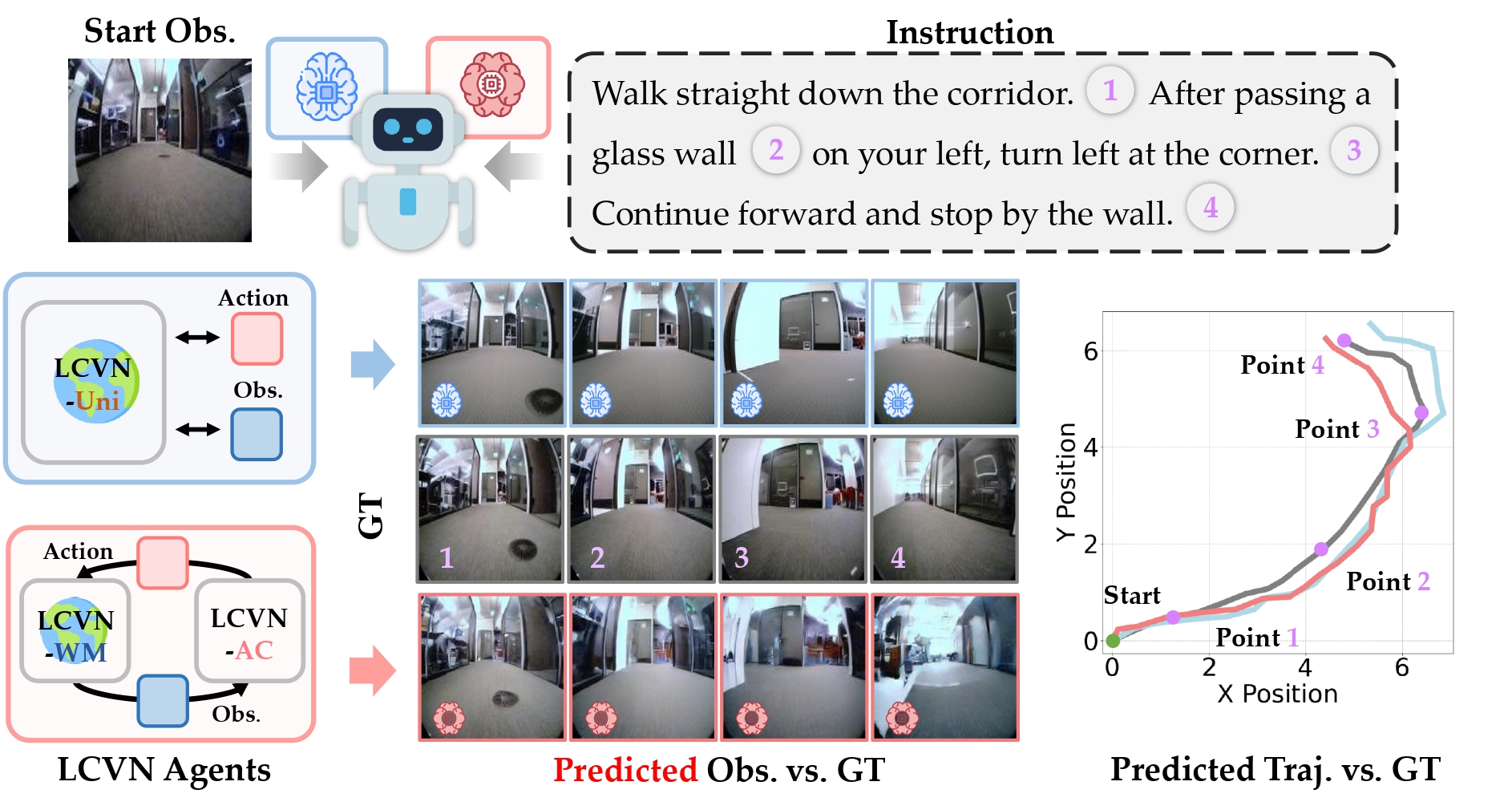
Human-Aware Vision-and-Language Navigation
In Advances in Neural Information Processing Systems (NeurIPS), Spotlight presentation, 2024
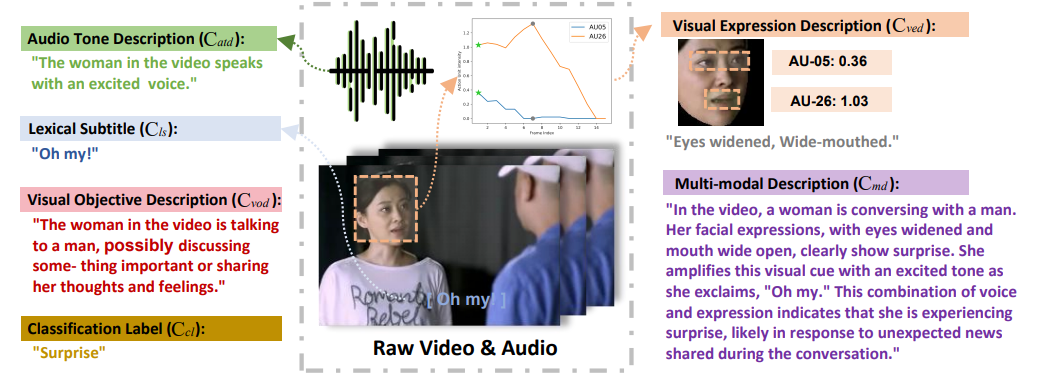
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
In Advances in Neural Information Processing Systems (NeurIPS), 2024
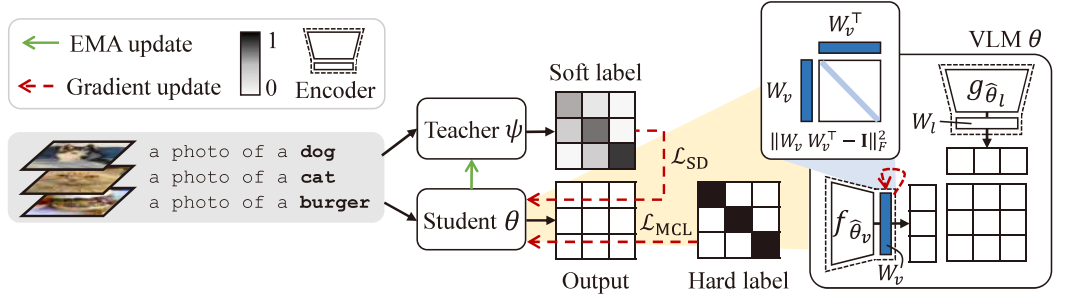
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
In Advances in Neural Information Processing Systems (NeurIPS), 2024
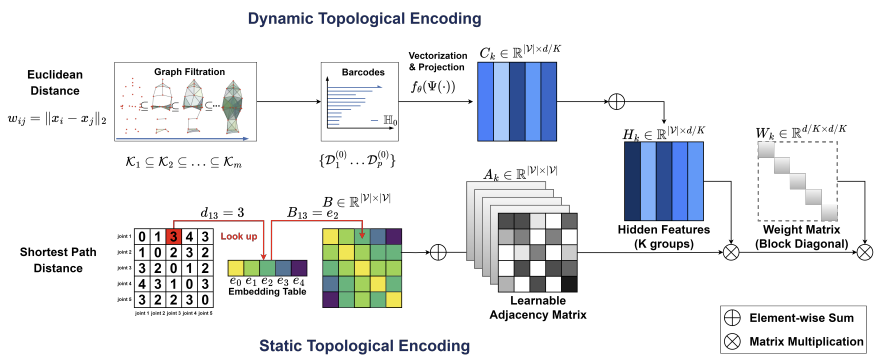
BlockGCN: Redefine Topology Awareness for Skeleton-Based Action Recognition
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
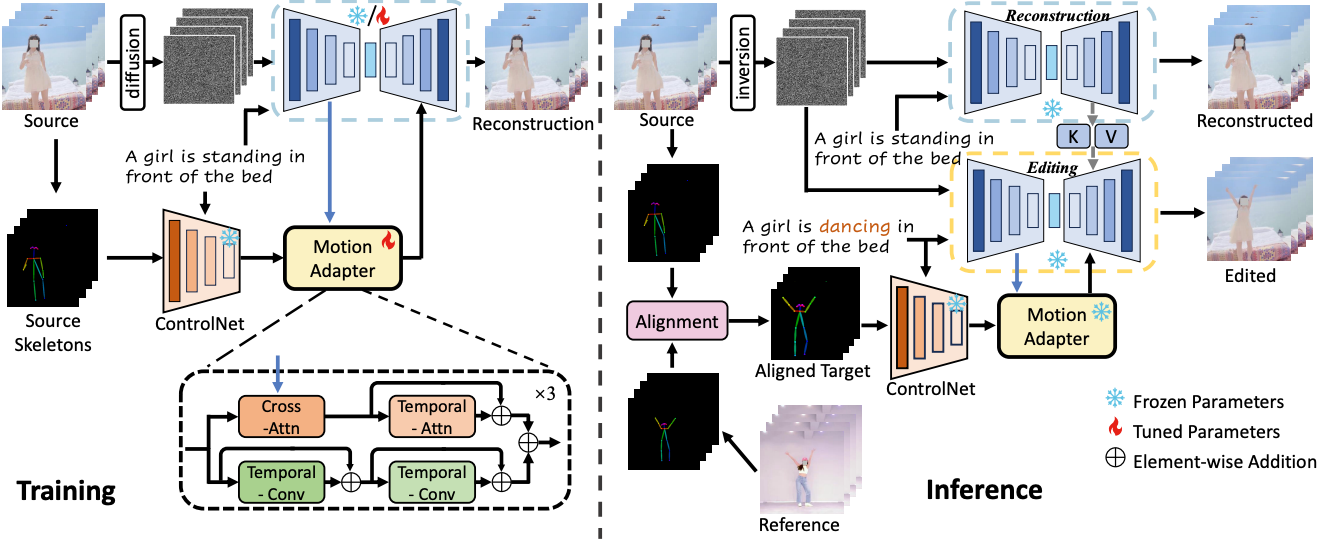
MotionEditor: Editing Video Motion via Content-Aware Diffusion
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
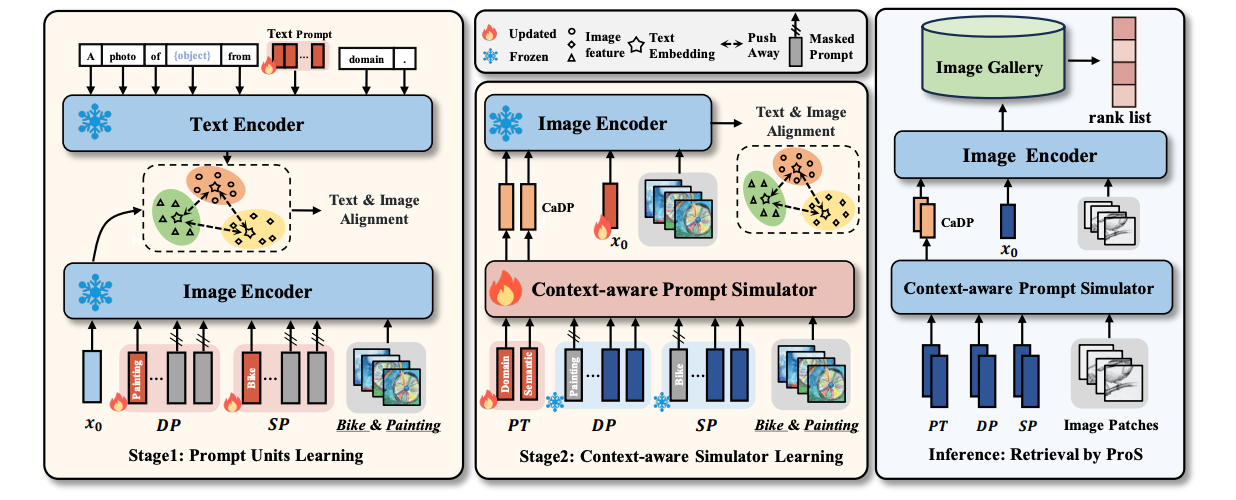
PROS: Prompting-to-Simulate Generalized Knowledge for Universal Cross-Domain Retrieval
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
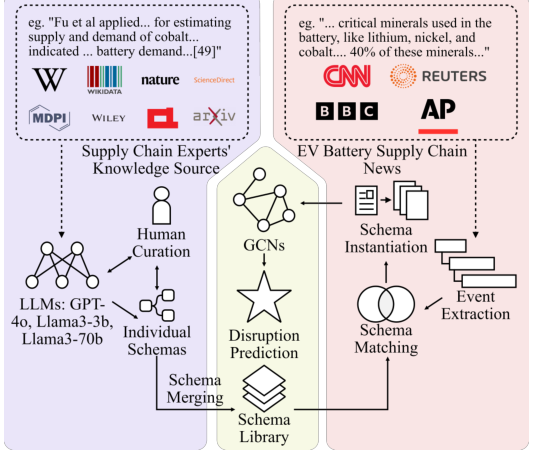
SHIELD: LLM-Driven Schema Induction for Predictive Analytics in EV Battery Supply-Chain Disruptions
In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Industry Track Oral presentation, 2024
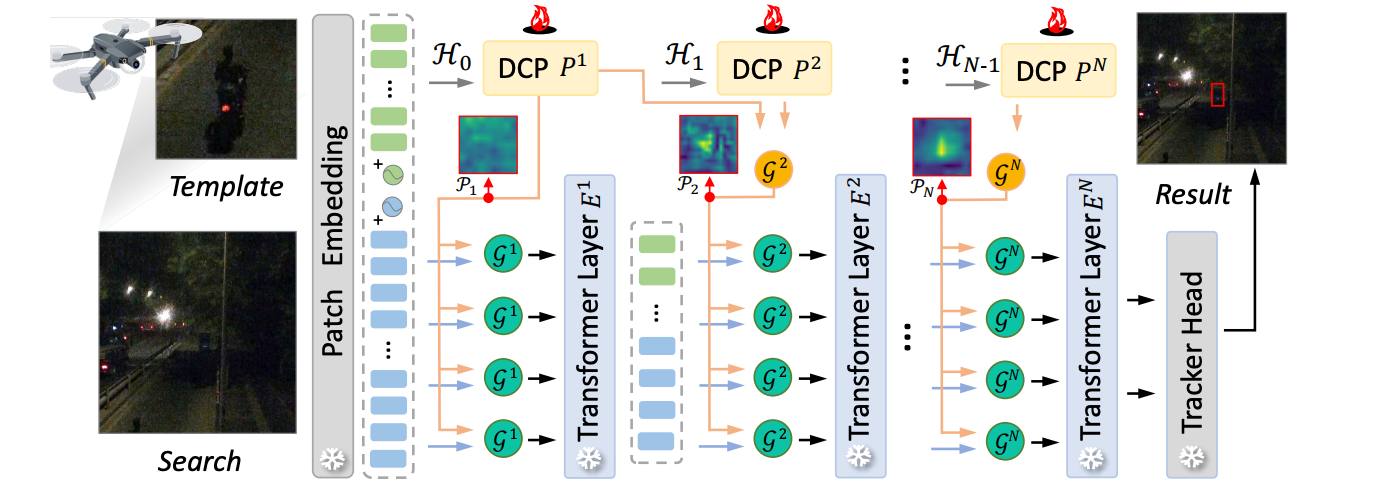
DCPT: Darkness Clue-Prompted Tracking in Night-Time UAVs
In IEEE International Conference on Robotics and Automation (ICRA), 2024

FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024


SemEval 2024
MIPS at SemEval-2024 Task 3: Multimodal Emotion-Cause Pair Extraction in Conversations with Multimodal Language Models
In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval), 3rd place, 2024
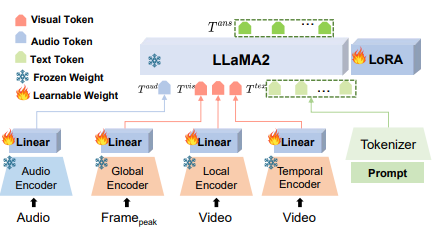
MRAC 2024
SZTU-CMU at MER2024: Improving Emotion-LLaMA with Conv-Attention for Multimodal Emotion Recognition
In Proceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing, 1st in MER24@IJCAI and MRAC24@ACM Multimedia, 2024
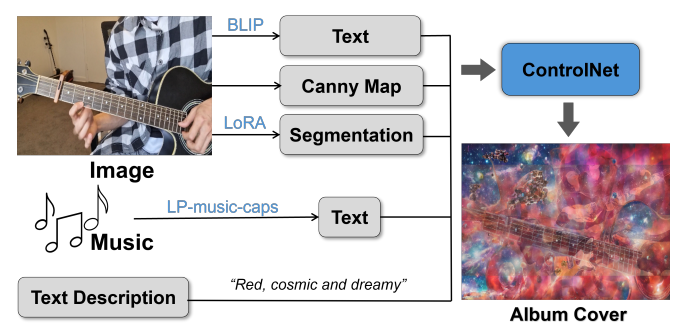
CIKM 2024 · Demo
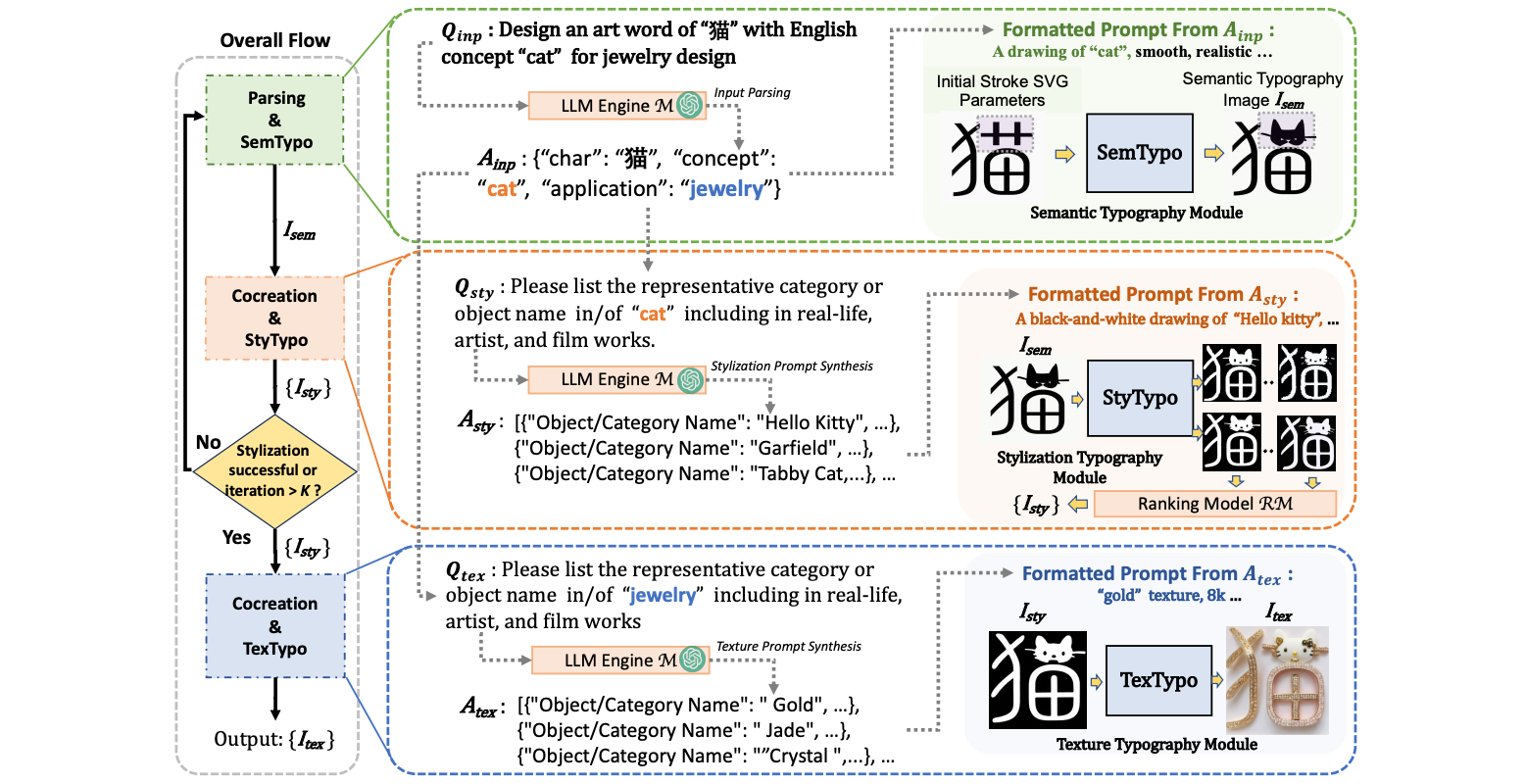
Music2P: A Multi-Modal AI-Driven Tool for Simplifying Album Cover Design
In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM), Demo Track, 2024

arXiv 2024
2023
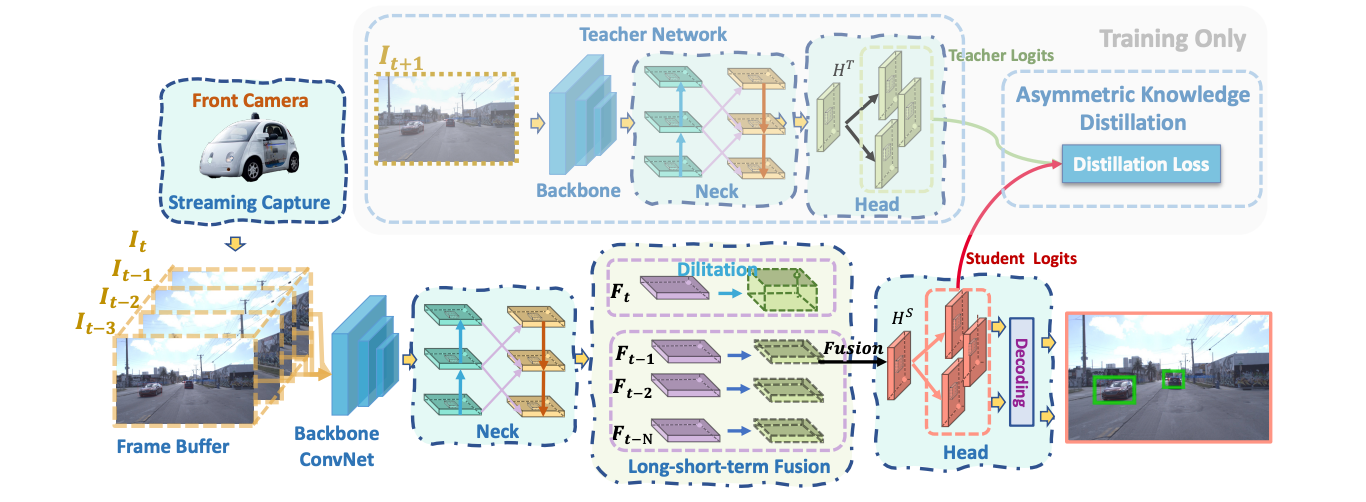
DAMO-StreamNet: Optimizing Streaming Perception in Autonomous Driving
In International Joint Conference on Artificial Intelligence (IJCAI), 2023
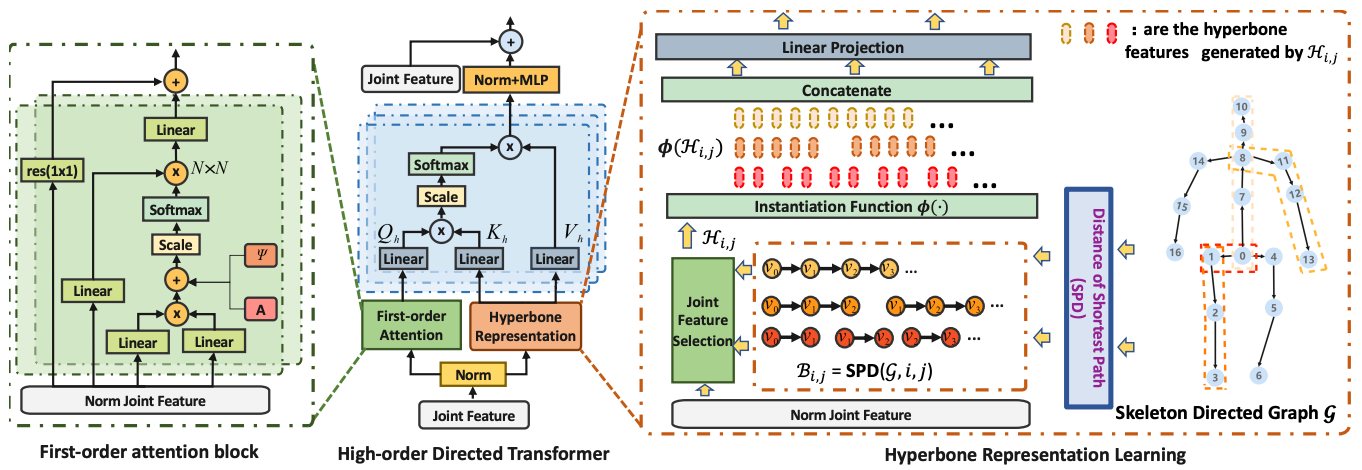
HDFormer: High-Order Directed Transformer for 3D Human Pose Estimation
In International Joint Conference on Artificial Intelligence (IJCAI), 2023
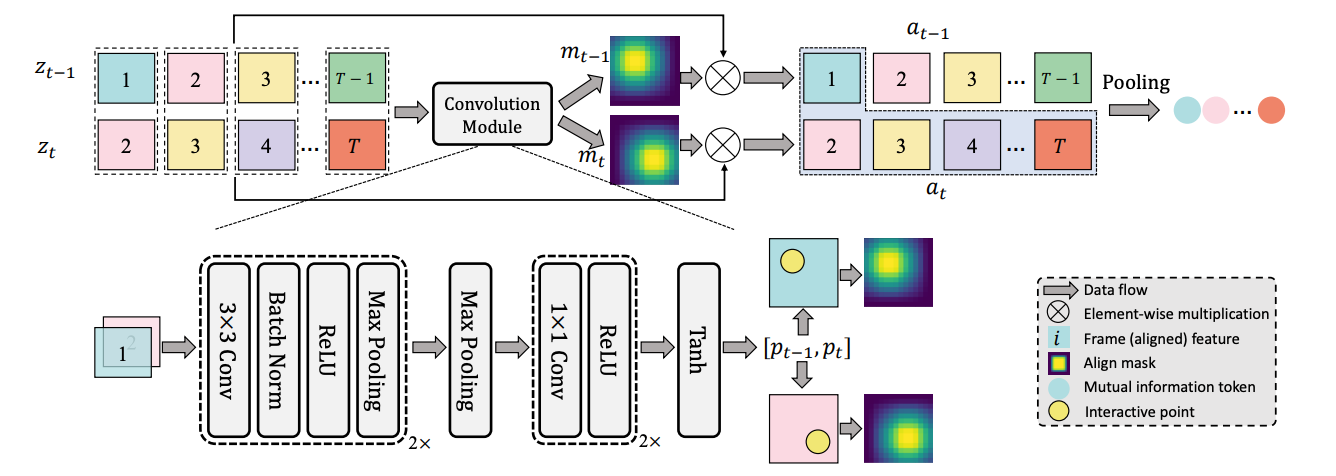
Implicit Temporal Modeling with Learnable Alignment for Video Recognition
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oral presentation, 2023
ChartReader: A Unified Framework for Chart Derendering and Comprehension
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
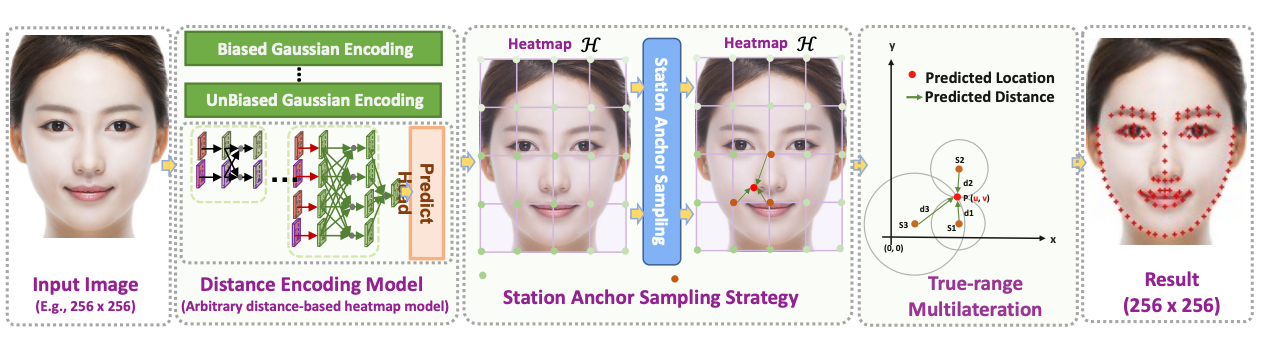
KeyPosS: Plug-and-Play Facial Landmark Detection through GPS-Inspired True-Range Multilateration
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2023
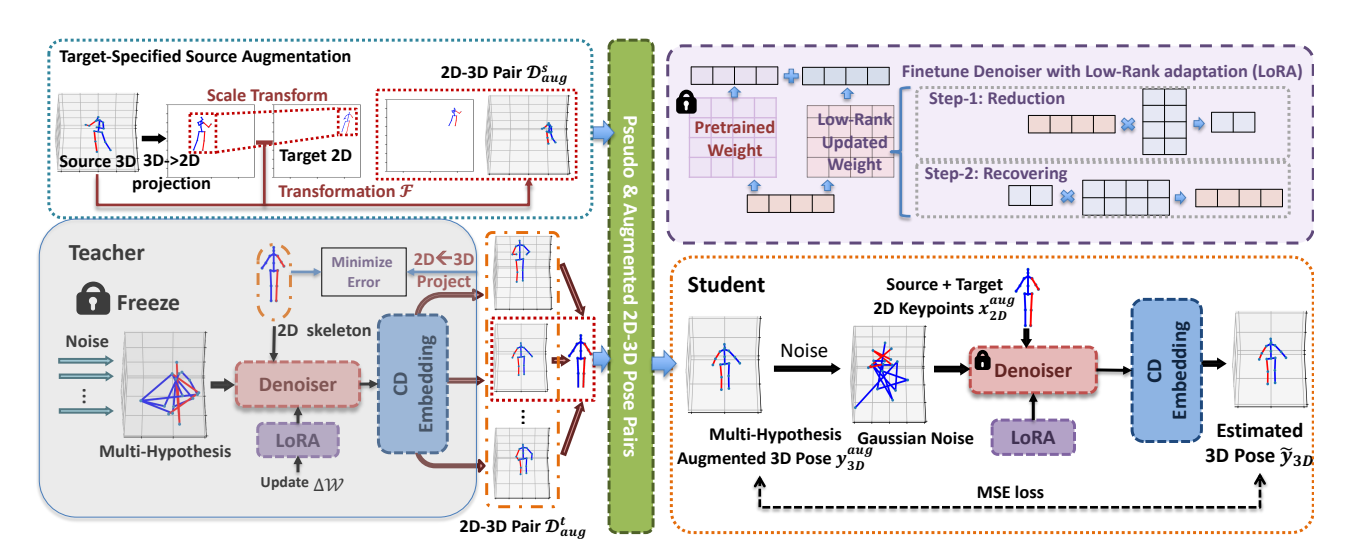
Posynda: Multi-Hypothesis Pose Synthesis Domain Adaptation for Robust 3D Human Pose Estimation
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2023
Robust Automatic Detection of Traffic Activity
U.S. DOT / Mobility21 Final Research Report, 2023
ICASSP 2023
LongShortNet: Exploring Temporal and Semantic Features Fusion in Streaming Perception
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
ICASSP 2023 · Oral
ProContEXT: Exploring Progressive Context Transformer for Tracking
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Oral presentation, 2023
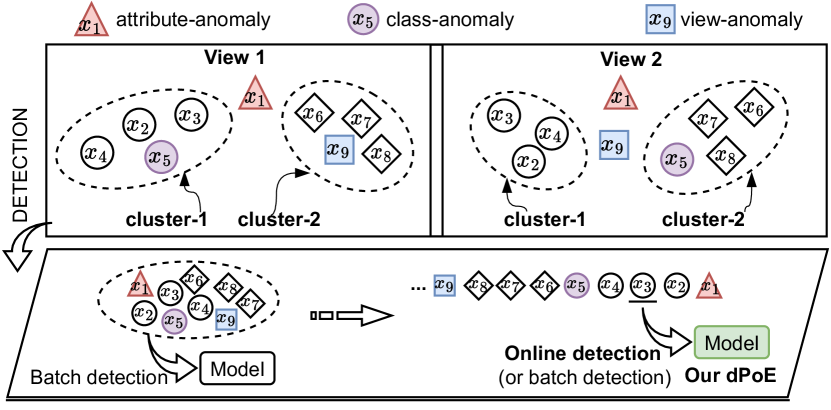
ACM MM 2023
Debunking Free Fusion Myth: Online Multi-View Anomaly Detection with Disentangled Product-of-Experts Modeling
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2023

ACM MM 2023
Improving Anomaly Segmentation with Multi-Granularity Cross-Domain Alignment
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2023
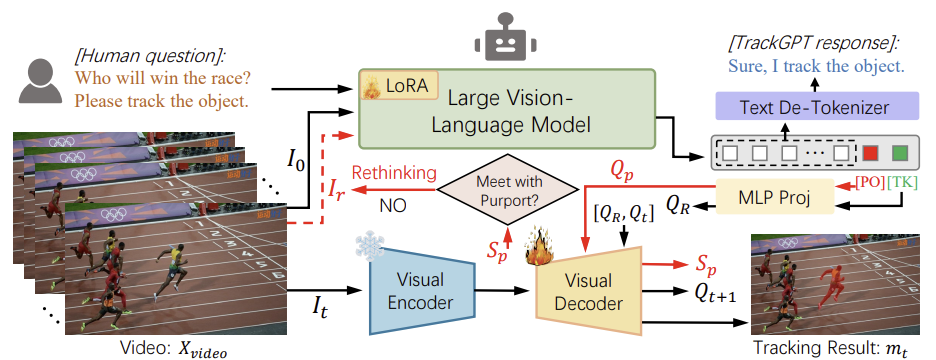
arXiv 2023
≤ 2022
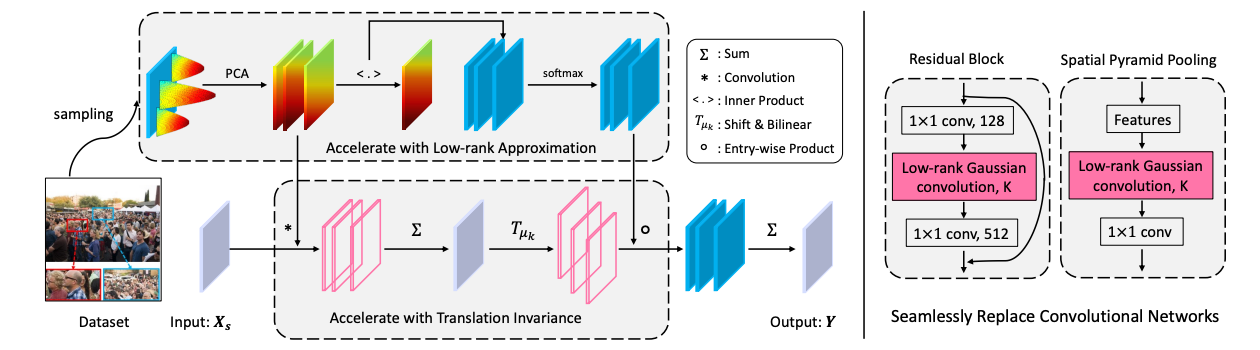
Rethinking Spatial Invariance of Convolutional Networks for Object Counting
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
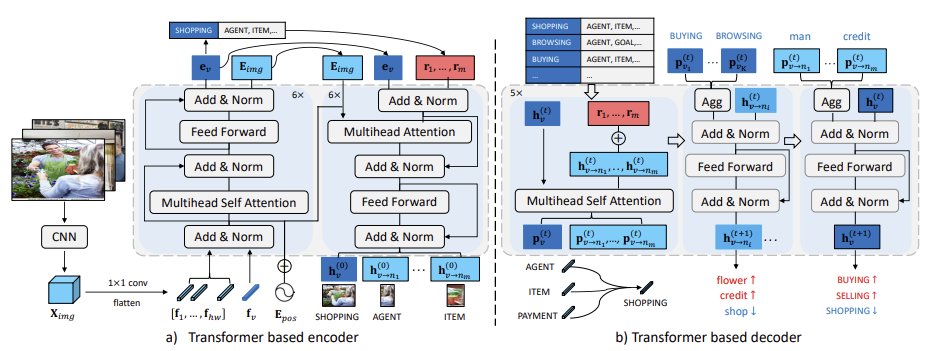
GSRFormer: Grounded Situation Recognition Transformer with Alternate Semantic Attention Refinement
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), Oral presentation, 2022
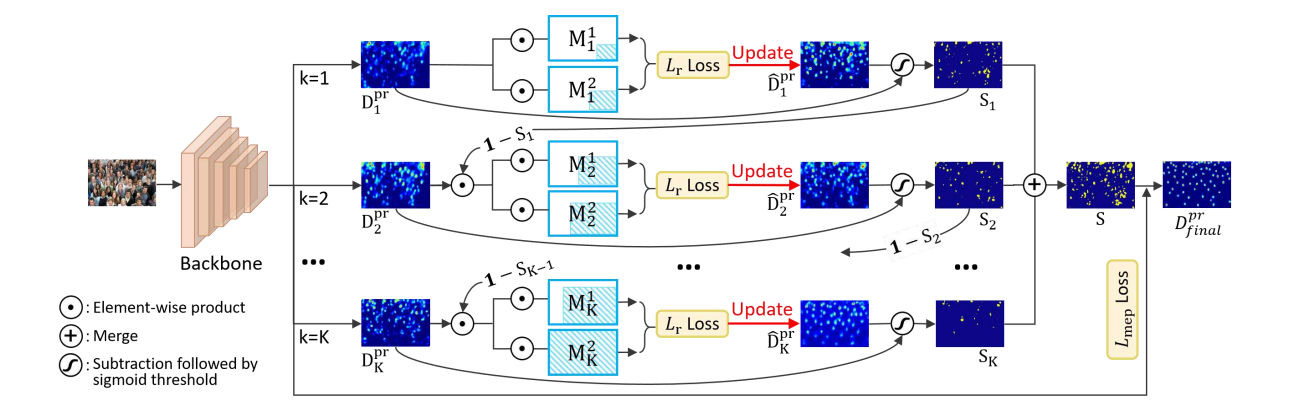
Learning Spatial Awareness to Improve Crowd Counting
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oral presentation, 2019
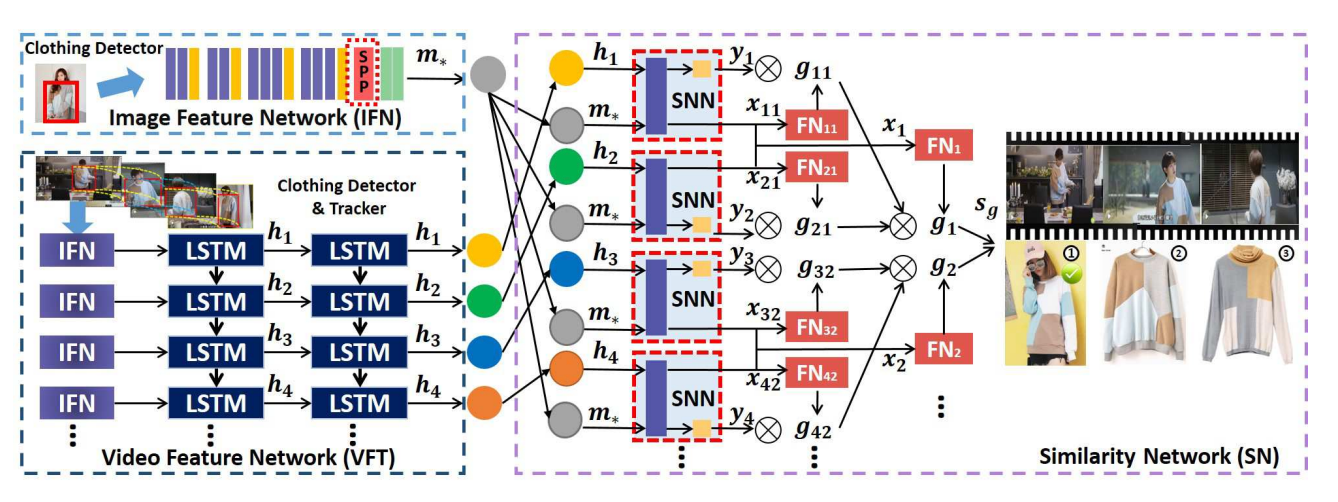
Video2Shop: Exact Matching Clothes in Videos to Online Shopping Images
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Special Oral presentation, 2017
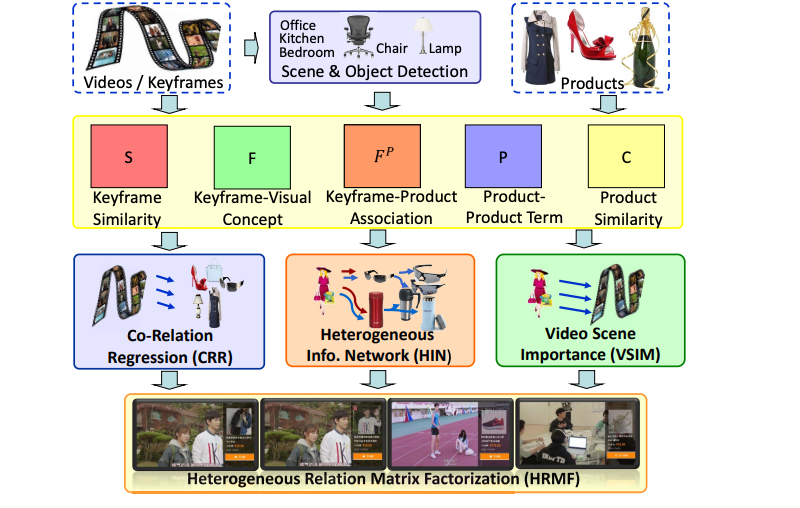
Video eCommerce++: Toward Large-Scale Online Video Advertising
IEEE Transactions on Multimedia (TMM), 2017

ICASSP 2020
Stacked Pooling for Boosting Scale Invariance of Crowd Counting
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020
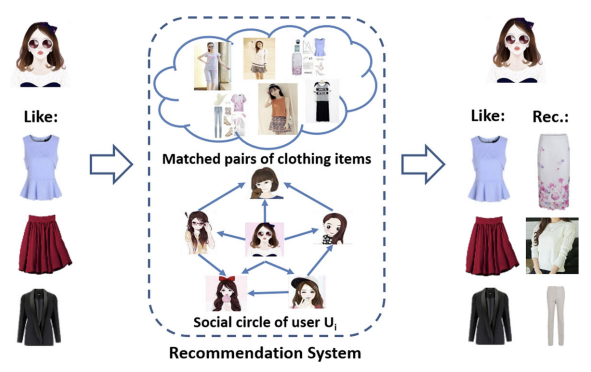
MTAP 2018
Personalized Clothing Recommendation Combining User Social Circle and Fashion Style Consistency
Multimedia Tools and Applications, 2018
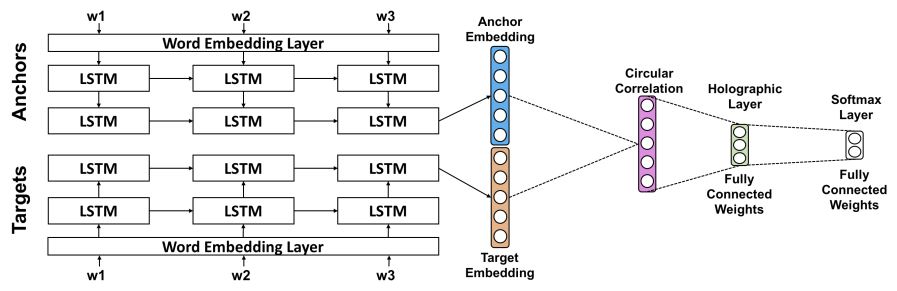
TRECVID 2017
VIREO@TRECVID 2017: Video-to-Text, Ad-hoc Video Search and Video Hyperlinking
TREC Video Retrieval Evaluation (TRECVID), 2017
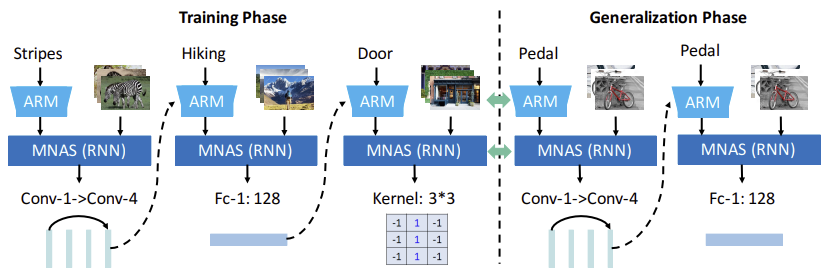
ACM MM 2018 · Spotlight
Learning to Transfer: Generalizable Attribute Learning with Multitask Neural Model Search
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), Spotlight presentation, 2018
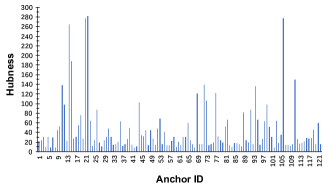
ICMR 2017 · Special Oral
On the Selection of Anchors and Targets for Video Hyperlinking
In Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR), Special Oral presentation, 2017
TRECVID 2017
Minimizing Risk in Video Hyperlinking
TREC Video Retrieval Evaluation (TRECVID), keynote, 2017
ACM MM 2017 · Oral
Video eCommerce: Towards Online Video Advertising
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), Oral presentation; ACM-SCF Best Student Paper, 2017

ACM MM 2018 · Oral
GNAS: A Greedy Neural Architecture Search Method for Multi-Attribute Learning
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), Oral presentation, 2018

ACM MM 2019
Improving the Learning of Multi-Column Convolutional Neural Network for Crowd Counting
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2019
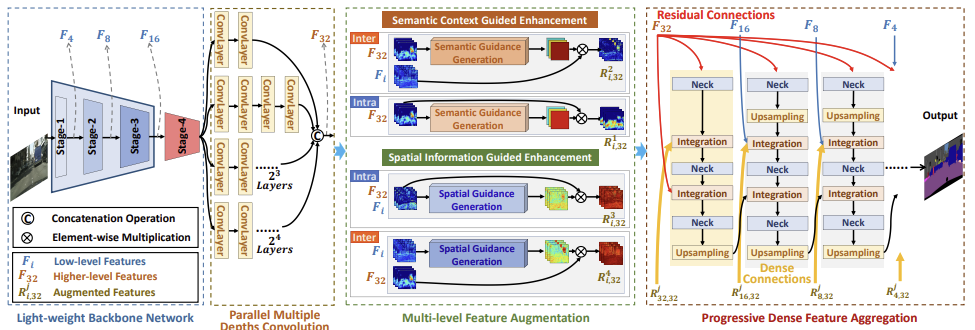
ACM MM 2022
Real-Time Semantic Segmentation with Parallel Multiple Views Feature Augmentation
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2022
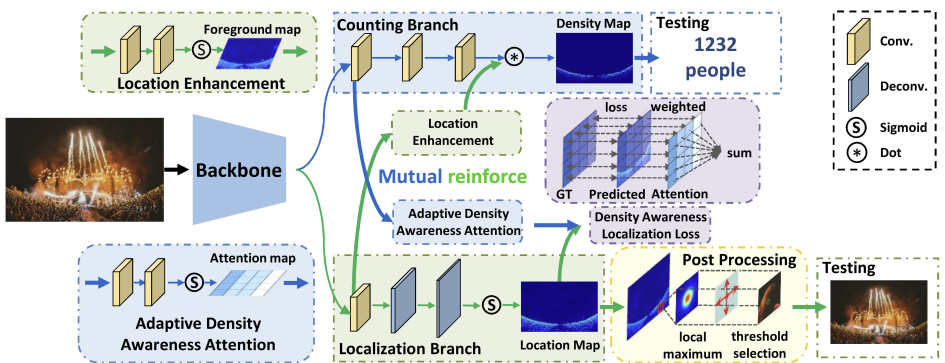
ACM MM 2022
CrossNet: Boosting Crowd Counting with Localization
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), 2022

ACM MM 2018 · Oral
Multi-View Image Generation from a Single View
In Proceedings of the ACM International Conference on Multimedia (ACM Multimedia), Oral presentation, 2018
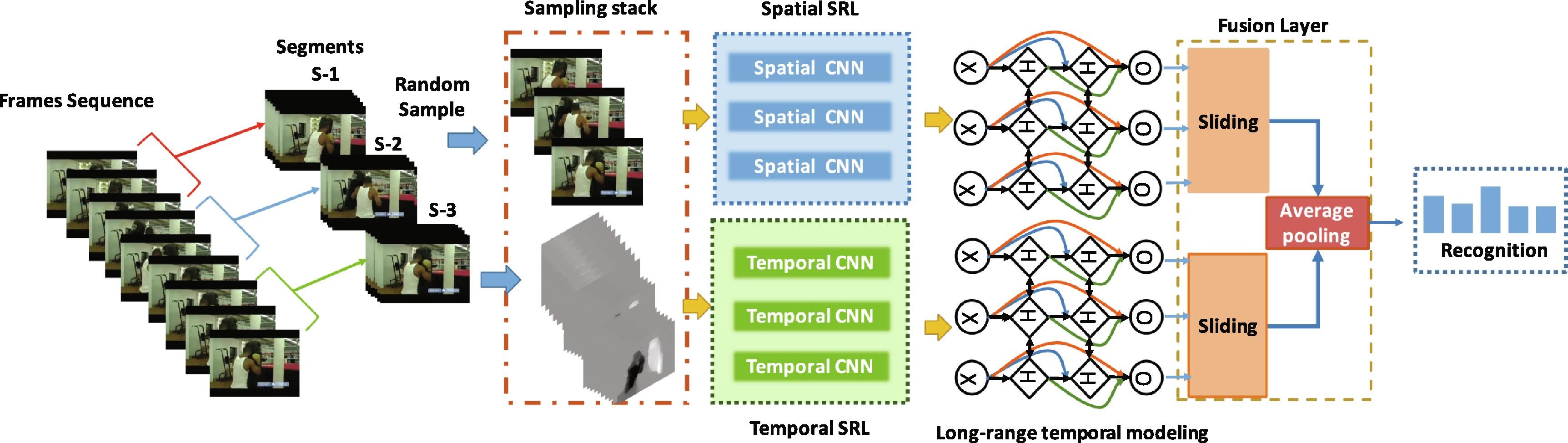
Neurocomputing 2021
DB-LSTM: Densely-Connected Bi-Directional LSTM for Human Action Recognition
Neurocomputing, 2021

NeurIPS Workshop 2018
Perceiving Physical Equation by Observing Visual Scenarios
NeurIPS Workshop on Modeling the Physical World, 2018

IJCAI 2020
Generating Person Images with Appearance-Aware Pose Stylizer
In International Joint Conference on Artificial Intelligence (IJCAI), 2020
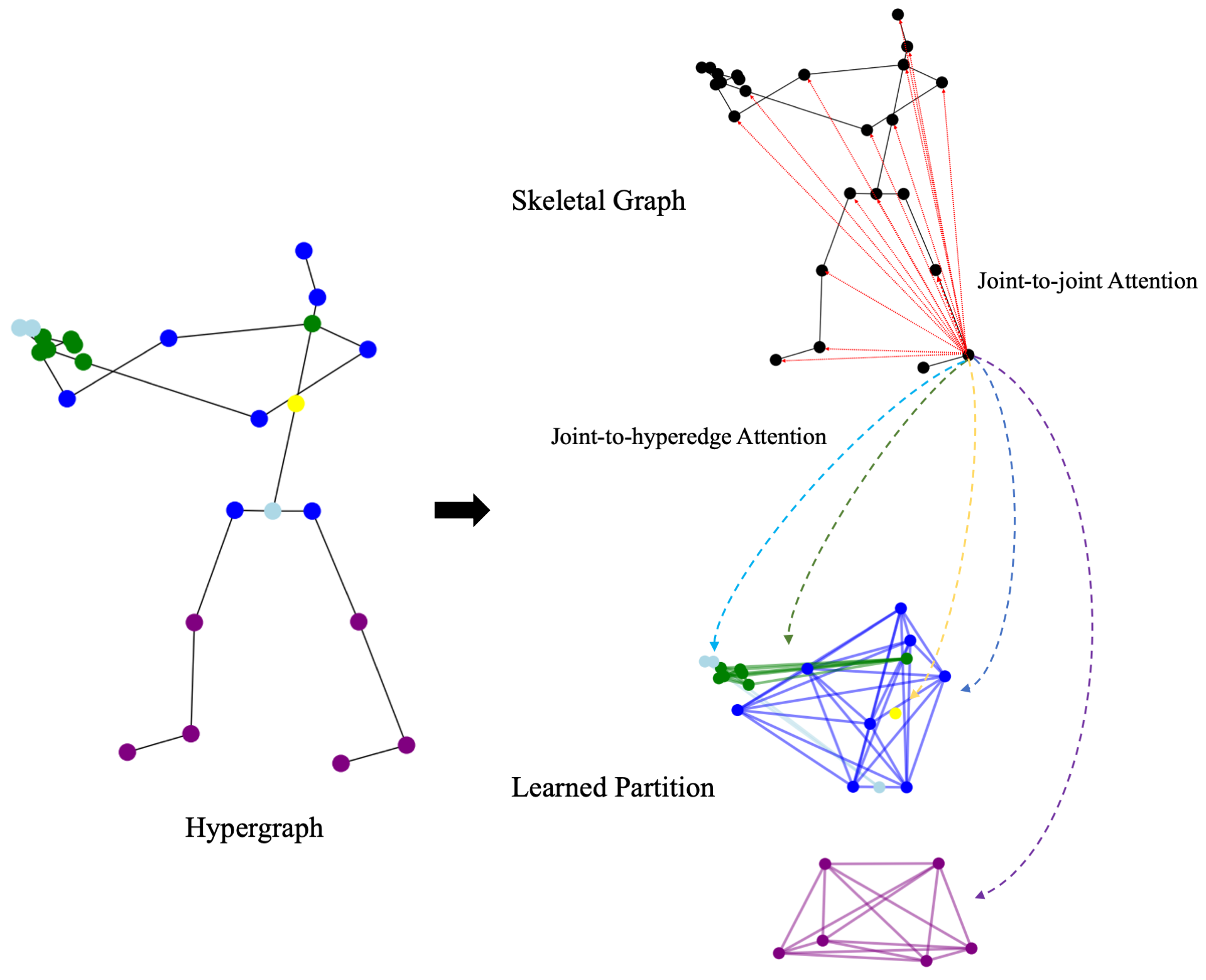
arXiv 2022
Patents

Patent 2020